
I was glad to speak with Sahil M Bansal, Enterprise Product Marketing Lead at CodeRabbit, about how AI is reshaping one of the most critical and time-consuming parts of software development: code reviews. In our conversation, Sahil shared how CodeRabbit applies large language models to perform deep, context-aware analysis that goes far beyond syntax or linting checks, identifying logic bugs, race conditions, memory leaks, and even exposed credentials before they ever reach production.
We also discussed how the rise of “vibe coding” and AI-generated code has created new challenges for engineering teams, and why independent AI code reviewers are becoming essential for maintaining trust, speed, and consistency in modern development workflows. Sahil explained how CodeRabbit’s context-engineering approach combines repository data, dependency graphs, MCP integrations, and verification agents to minimize hallucinations and ensure reliable results, helping teams cut review times by up to 90% and ship cleaner code faster.

These ideas will be at the heart of our upcoming Data Phoenix webinar "End-to-End Agentic Coding: Automating Code Gen + Code Reviews," taking place on October 21st at 9 AM PDT (18:00 CEST). Together with Sahil, we will explore how agentic workflows in the CLI can automate the entire development loop, from code generation to review and fixes, while keeping developers in control.
Now, let’s jump into the full interview, packed with insights on AI, context engineering, and what it really takes to trust your code.
Sahil, welcome to Data Phoenix! Let’s kick off our chat with something a bit unconventional. If CodeRabbit were a superhero, what would its superpower be, and why?

Batman. He doesn’t need any supernatural powers. He is just very good at using all the things available to normal humans, coupled with his intellect and resources, in a way that prevents bad actors from bringing down society. CodeRabbit relies on the same information that is available to any developer but like Batman it uses that information with its built-in context-engineering approach and resources (LLM tokens) to squash all the bugs (bad actors) before they hit production (impact society).
Tell us about yourself and your role at CodeRabbit.
Sometimes I like to joke that my job is to translate engineering-speak to customer-speak. They really are two different languages. The industry likes to call this role as Product Marketing. I call it understanding what engineering has built and figuring out why customers will care about it. I’ve been in similar roles for about a decade across cloud infrastructure, kubernetes monitoring and now AI dev-tools space.
How would you describe CodeRabbit to someone unfamiliar with it?
It's your friendly neighborhood bug-buster. We pioneered the space of AI code reviews to help developers get a second pair of eyes on their code. Let me give you an example: if you cook dinner at home, you don’t say “wow, this is such a delicious meal” or “i must be a good cook”. You ask your friends, family or partner for an opinion, “hey, how does the food taste?”. We do that but for your software code. We are the independent code reviewer that helps you make sure you don’t accidentally ship bugs into production. We help you identify and fix issues in your code acting as an independent review and governance layer.
What sets CodeRabbit apart from other solutions?
The secret sauce with any kind of LLM-based solution lies with how you build and feed context to the LLM. When it comes to code reviews, simply telling the LLMs what the lines of code that have changed is not enough. You have to understand the user intent behind those changes, the downstream dependencies that might change, or the specific rules that a user wants their code to be validated against. Building this kind of context-engineering approach helps you find much more deep seated issues in your code such as potential refactors, race conditions, memory leaks, etc. Those are far more critical to catch than, say, simple syntactical issues.
Who is the primary target audience for CodeRabbit?
I want to say software developers but aren’t we all software developers now? Or at least some level of vibe coders? Really anyone who is generating new code, whether that’s with AI coding agents or the 20% of people who still code manually, we all need an independent code reviewer in our lives. In a way, CodeRabbit is for anyone who is building and shipping any kind of software.
You already have 10,000+ customers and have reviewed over 13 million pull requests. From this broad user base, what patterns do you see? Are there common challenges those teams face which drew them to CodeRabbit? Any particular industries or team sizes where it’s especially popular?
The bigger the team size, the more bottlenecked the code review process tends to be unless you are utilizing some sort of intelligent automation to help you out. We’ve had customers like Groupon who shared that their manual code review to production timeframe was more than 3 days when they were still reviewing code manually. After implementing AI code reviews, they got that down to less than an hour. That’s a huge value in time savings! So, we see more of the value showing up the bigger the team sizes get.
But there are also some industries where the cost of shipping a bug to production can be extremely critical. Example: banks, hospitals, automobile manufacturers, etc. are all extremely sensitive to code quality because the cost of production downtime can be huge for them. We see a fair bit of adoption in such industries too.
What specific needs or pain points does CodeRabbit address for your users? For example, does it help junior developers catch up to best practices, or save senior engineers time on tedious checks? What kinds of issues were slipping through the cracks before that CodeRabbit can now catch?
It is very valuable for early career developers to have senior engineer level code reviews available to them 24x7. But we also hear from customers with highly distributed teams that are spread across multiple time zones that they really value their PRs not sitting idle for days and the AI code reviews kick in immediately when a PR is opened. Typically we see 30-50% faster PR review times and 40-50% fewer bugs in production compared with manual code reviews and after using CodeRabbit for a few months.
Also, PR reviews are just one part of the story. CodeRabbit gives you flexibility to run code reviews wherever your developers want them: in the CLI, in the IDE or in the Pull Requests. CLI and IDE based reviews are perfect when you want your code reviewed locally and PR reviews are of course critical when reviewing the whole team’s code together in one place before shipping.
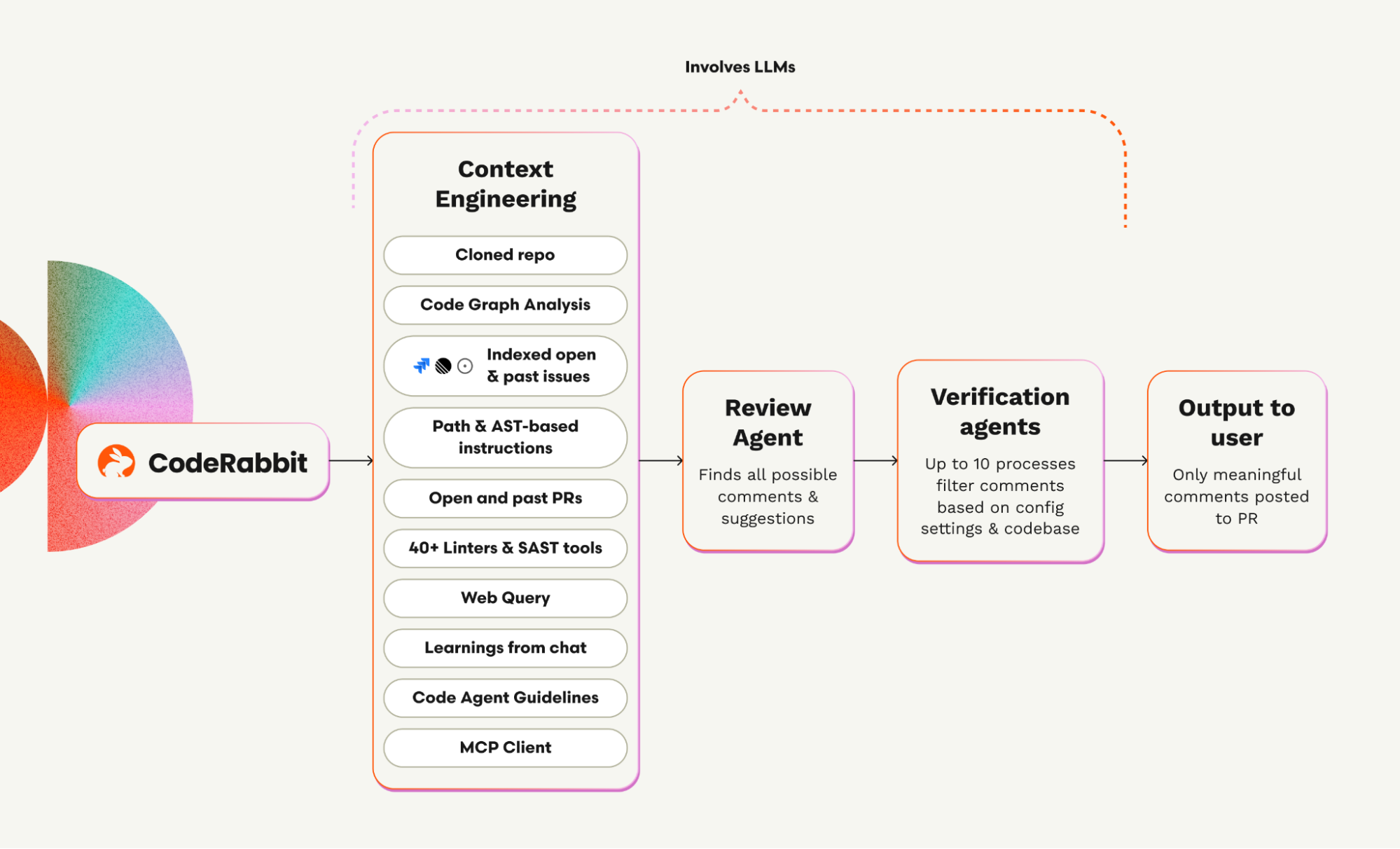
How does AI power CodeRabbit’s code reviews under the hood? Could you give us a peek into how it works, for instance, how do you combine large language models with code analysis? We’ve heard CodeRabbit uses AST (abstract syntax tree) analysis and a code graph for context, plus LLMs for reasoning. How do these pieces come together to produce a human-like review?
Everything starts with cloning your repository. We keep a clone of your repo in a secure sandbox, then build a code graph to understand dependencies across your function calls. Then we look at the user intent: is there a github or jira ticket attached to your PR? We also have an MCP client that you can integrate with, say, your Notion or Figma MCP servers to give us access to your requirements doc or architecture diagrams or Sentry logs. We also look at your coding agent rules files such as cursor rules, copilot instructions etc. You can also provide your own custom review files. All of this adds on to the context that’s packaged into our prompts and helps the LLMs get more info that they need to have a full picture view of what your codebase is doing, what your intentions are, and whether you have some custom review rules you’d like to use.
This is effectively the same process that a human would’ve also followed except you get it now in an automated fashion and from a tool that won’t get cranky or mad at you for missing a semi-colon.
What range of issues can CodeRabbit detect during a review? Does it go beyond simple style or linting suggestions? For example, can it catch deeper problems like logic bugs, potential race conditions or security vulnerabilities?
Simple style guide validation or linting checks are table stakes. We do that of course but because of our deep context engineering approach, we can find much more deep-seated issues.
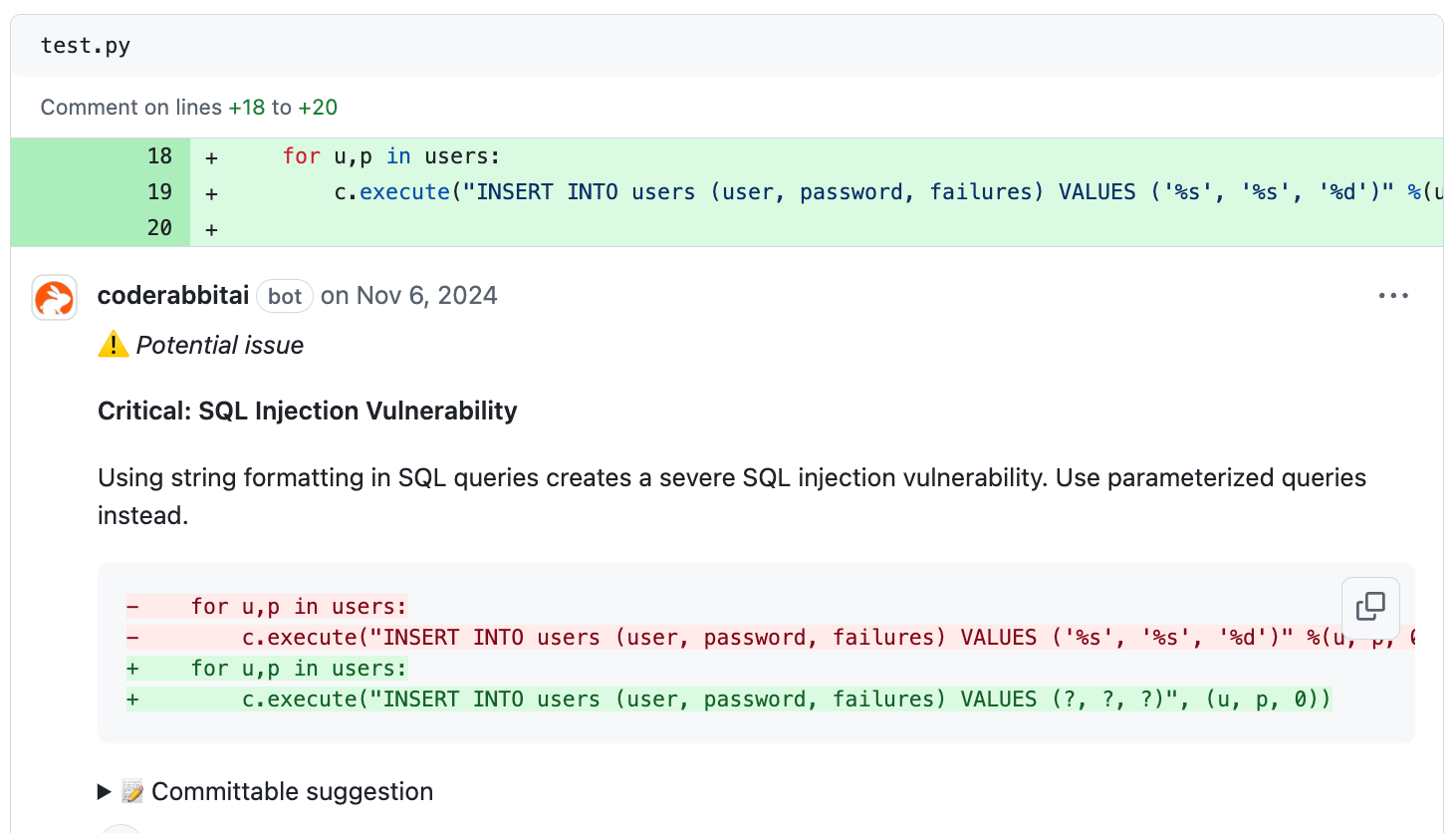
Example as you mentioned, logical or functional bugs, race conditions or SQL memory leaks, injection vulnerabilities, error handling, refactors that would make your code more maintainable, even exposed credentials which you’d be surprised how common they can be especially in a vibe coding era. We encounter these all the time.
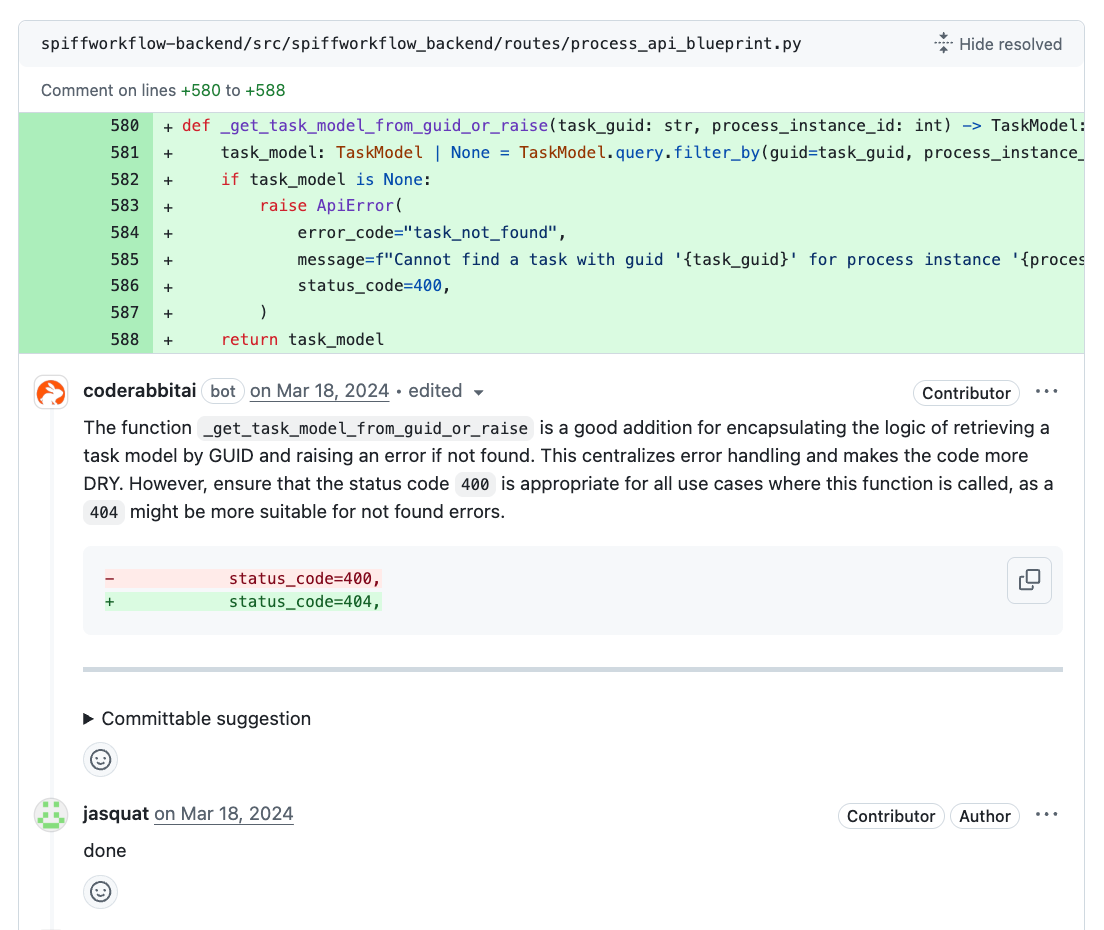
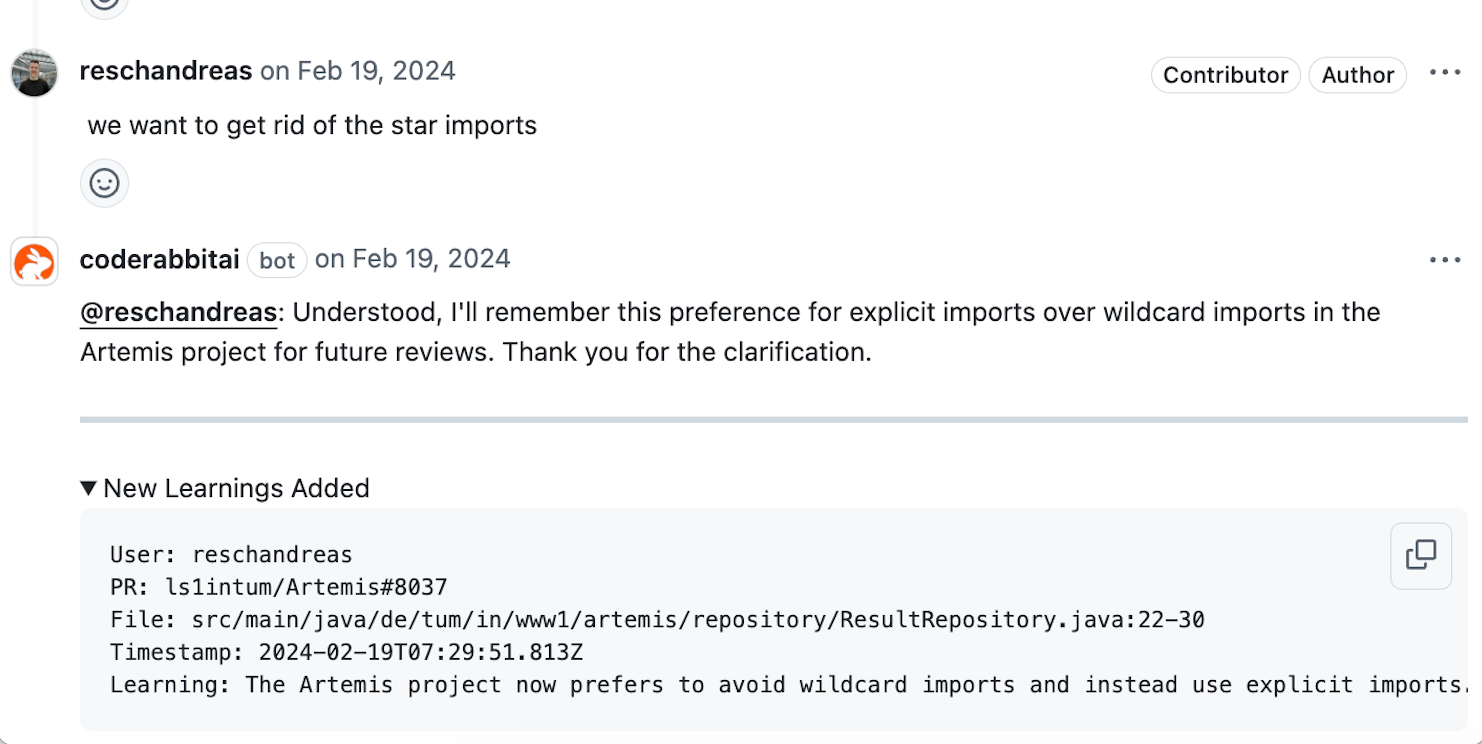
The platform learns from user feedback over time. How does that adaptive learning function? For instance, if my team prefers a certain code style or has specific guidelines, how does CodeRabbit remember and incorporate that in future reviews?
Users can give feedback to CodeRabbit and that feedback is recorded and used in all subsequent reviews. You can simply chat with it in your PR like you would chat with a human reviewer. Ask questions, provide feedback, counter-question its assumptions or delve deeper into why certain review comments were made. All of these are recorded as learnings. For example: the AI might recommend that if you are importing many different classes, maybe use a wildcard import instead. But perhaps you don’t want to do wildcard imports, in that case you can simply chat with it and let it know your preference and it won’t recommend wildcard imports in future.
How do you ensure the AI’s feedback is accurate and relevant? AI can sometimes hallucinate or give wrong advice. What safeguards are in place so that CodeRabbit’s comments and suggestions are reliable? (For example, do you run the code through static analyzers or tests to validate AI suggestions, or use other verification techniques to keep a high signal-to-noise ratio?)
We have a built-in verification agent that reduces the chances of LLM hallucination making it through to your review comments. Under the hood the agent runs shell scripts that in an iterative loop (up to 10 times) to make sure the LLM comments are relevant, make sense if they were applied to the code, do not make up APIs or function names, and the human reviewer can also see what the verification agent saw.
Data privacy and security are big concerns with AI developer tools. How does CodeRabbit protect a company’s code? For instance, do you retain any code or use it to train models? What measures have you implemented to ensure sensitive codebases remain secure?
None of our users code is used to train LLMs. We have agreements in place with both OpenAI and Anthropic to ensure LLMs are not trained on your code. Also, all of your code is discarded after a rolling period of 7-days if there are no further reviews. During that time period while your code is cached, we keep it secure in a sandbox environment that is not exposed externally. We run the analysis on that copy of your code and prompt the LLMs. For customers with even more strict requirements we also offer a completely self-hosted container image where the entirety of CodeRabbit runs in your self-hosted cloud VPC or even on-prem environment.
“Ship faster with agentic Chat” – CodeRabbit includes an agent-like assistant in the workflow. Can you explain this feature? What kind of multi-step tasks can the CodeRabbit agent handle via chat?
Mainly docstrings and unit test generation. You know, all the fun stuff that developers absolutely love to do. But seriously, the best use case of AI is to do repetitive stuff that is boring but important. Can’t get more important than updating docstrings and unit tests. You can simply chat with coderabbit and ask it to validate and update your docstrings file or generate a unit test file and they will be added on as a stacked PR.
Context is king in code reviews. Your recent blog post noted that code reviews done in isolation (just looking at code changes) miss the bigger picture, like business requirements or deployment configs. How does CodeRabbit bring in a broader context for reviews?
Through an array of different data sources. We look at your issue tickets such as Jira/Linear or Github issues to identify your project requirements, you can configure any remote MCP server you want and the agent with autonomously use the MCP server to fetch additional context that it may need, we also run a real-time web search if the LLM may not be fully up to date with the info needed to review some portions of the code (example: the latest security patch). There are more than 40 Linters that are built-in with best practices that are configured and you can provide your custom review instructions in the form of a path-based instruction and lastly we also analyze your past PRs and repo history to gather context about how similar issues may have been fixed in the path. All of these data sources feed into the context that we build around your code diff.
The rise of “vibe coding” has created new challenges for code quality. A recent report found 95% of developers now spend extra time fixing AI-generated code, and senior devs have effectively become “AI babysitters” for faulty AI output. It’s even led to the tongue-in-cheek job title “vibe code cleanup specialist” at some companies. What’s your take on this trend? How can tools like CodeRabbit help teams deal with the onslaught of AI-generated code and reduce the need for manual cleanup?

You know our marketing team was playing around with ideas on “vibe code cleanup specialist”. That’s really what we are. We may or may not have some of our marketing colleagues dressed up in hazmat suits at some of the upcoming conferences looking for bugs they can exterminate in your code. But seriously you are absolutely right in the sense that vibe coding does introduce a lot of potentially harmful bugs in your code. And AI coding agents struggle with evaluating their own code. Just like you or I would struggle to review and find typos in blogs that we wrote because it's really hard to review your own bug. Code review needs a completely different architecture and approach than code gen agents do. You need to understand the context, enforce best practices, and clean up after the vibe coding agent to keep the code functional and safe.
The AI code review space is heating up. We’ve seen startup rivals like Graphite raise significant funding and other tools emerging, not to mention big AI assistants (Anthropic’s Claude, Replit’s Ghostwriter, etc.) adding their own code review features. How do you stay ahead of the competition? What makes you confident that a dedicated platform like CodeRabbit can provide more value than, say, a built-in GitHub Copilot code review or other bundled solutions?
Almost all of our customers already use Claude, Copilot, Cursor etc and they understand that they need a code review tool that’s architecturally an independent layer on top of their code generation agent. Ai coding agents are very confident when they tell you that your code is ready for production but it really isn’t. So why can’t they catch their own mistakes before they get shipped? For the same reason that even before AI we never asked a developer to self-certify that they have reviewed their own code and it is bug free. Self-certification simply doesn’t work and that’s why we are seeing code review space emerge as a second-order effect of AI coding agents. It's really an independent product category and we welcome other independent code reviewers entering this space to grow this AI code review industry together.
time for a fight. which ai code review tool is your favorite?
— Forrest (@ForrestPKnight) September 23, 2025
CodeRabbit was early to identify the code review bottleneck from AI coding. Now that this is widely recognized, how has the conversation with customers changed? Are engineering leaders coming to you with concerns about code quality in the era of AI-assisted development? How do you position CodeRabbit as the “quality gate” for teams embracing tools like Copilot?
Yes, definitely. Initially the product growth was pretty much all product-led. Individual developers finding our product and trying it out. Most of those were smaller teams of, say, less than 50 developers. But now that CodeRabbit has more mindshare, we are expanding into customers with greater than a thousand developers in some cases. While the basics of code reviews don’t change, larger teams have their own different challenges. For example: many teams wanted us to have the ability to block their PRs from being merged if certain code quality criteria are not met. Two quick examples could be if there’s not enough docstrings or unit test coverage or if there are non-zero critical bugs that are unresolved then do not allow PRs to be merged. We are working on such quality gate features that have been requested by larger companies.
Congratulations on your recent $60 million Series B raise! What does this milestone mean for CodeRabbit as a company? How do you plan to deploy this capital? Is it more on product R&D, expanding the team, go-to-market, or something else?
Thank you! The company has been around for a little over 2-years and it's been a whirlwind of a ride. I’ve been in the industry for nearly 12 years now and I’ve never seen a platform shift happen so rapidly. The additional capital will help us keep pace with the customer demands by primarily expanding our engineering and sales teams. In fact we recently crossed 1T tokens served on OpenAI and our growth was acknowledged during the OpenAI DevDay.
How do you see the role of AI in software development evolving in the next few years, and where does CodeRabbit fit in that future? Do you envision a point where AI handles the bulk of code review autonomously, or will human engineers always be in the loop for final approval?
Predicting any trends in the age of Agentic AI is a fool’s errand. Things change so fast. What we knew 6 months ago is obsolete. However, we believe humans will remain in the loop for the final approval for the foreseeable future. Not simply because AI isn’t fool-proof yet but more importantly because it's your code, you should have the final say on how it works. We are here to help you and not to replace you. We use AI as a tool in many workflows and code reviews is just another one of them.
Tell us a bit about the team behind CodeRabbit. How would you describe your company culture, especially as you grow rapidly? What values or practices keep the team focused on innovation and quality?
Its rapidly growing team of about 100 people right now mostly based out of San Francisco and a bunch of folks in other cities across the globe. We value customer input above all else and firmly believe in keeping our ears to the ground so that we can react quickly and positively in this ever changing landscape.

Are you hiring, and if so, what kind of talent are you looking to add? As you scale the company, which roles or skill sets are critical for your next phase of growth?
Yes, we are aggressively hiring across all functions, especially engineering, GTM and sales. I encourage all interested candidates to check out our website coderabbit.ai for the open roles.
For engineering leaders on the fence about using AI in their code review process – any words of wisdom? Many teams know they need to embrace AI to stay efficient, but they worry about trust and control. How would you advise them to approach a tool like CodeRabbit or AI in general to improve their workflows?
The one thing I always ask engineering leaders is what are your personal KPIs? Are you, as an engineering leader, judged by how quickly your engineers are generating code or by how quickly and efficiently you are shipping features? Inevitably the answer is the latter. And if you probe a little closely, you will realize that the slowest bottleneck in terms of shipping features is no longer code generation but it is code reviews. Unless you have a strategy on how to loosen that bottleneck, your team won’t be fully realizing its potential with implementing Gen AI solutions. That’s what I recommend that engineering leaders should think about.
Where can people learn more or try out CodeRabbit? If our audience is interested in testing it or seeing it in action, what’s the best way for them to get started (I know you offer a free 14-day trial)? Also, how can they follow your company’s updates (feel free to mention your blog, Discord, social handles, etc.)?
Check our our website at coderabbit.ai and you can start your free 14-day trial and hook up CodeRabbit to your preferred Git platform. Or if you prefer to start in the CLI or IDE then you can do that do. Simply search for the CodeRabbit extension in the IDE extensions marketplace or run a simple curl command to install our CLI agent. With either approach you should be able to get your code reviewed in under 10 mins and catch all those pesky vibe coded bugs.
You can also follow us on the socials (Linkedin, twitter, discord etc.) to keep up with the company’s updates
— CodeRabbit (@coderabbitai) August 24, 2025
Sahil, thank you for this insightful conversation. It’s been a pleasure learning how CodeRabbit is shaping the future of AI-powered code reviews and helping developers ship cleaner, safer code faster. I’m really looking forward to your session at our upcoming webinar. See you there!
Thank you, Dmytro, and thanks to the Data Phoenix team for inviting me. I really enjoyed our chat and look forward to joining the webinar, where I’ll share more real-world examples and answer questions from the audience. See you on October 21st!





Comments