
Delivering on its previous statements, the company announced it would share pre-trained and instruction-fine-tuned variants for two open-source large language models in the 8B and 70B parameter categories. The release of the Meta Llama 3 models builds on Meta's commitment to "releasing early and often" so the community obtains access to the models while they are still in development. In the particular case of the Meta Llama 3 generation, the availability of these two text-based models marks the start of a path towards several goals, which include multilingualism and multimodality, in addition to longer context windows, and improved performance in reasoning, coding, and other core LLM capabilities.
The Meta Llama 3 models set a new performance standard for models in their size categories, partly due to their reduced false refusal rates, improved alignment, and increased diversity in model responses. Meta Llama 3 8B was tested against instruction-tuned variants of Google's Gemma 7B and Mistral 7B, while Meta Llama 3 70B was compared to the very recent Gemini 1.5 Pro and Claude 3 Sonnet to find that the former achieved best-in-class status, while the latter offers very competitive performance with very slight gaps in benchmark scores.
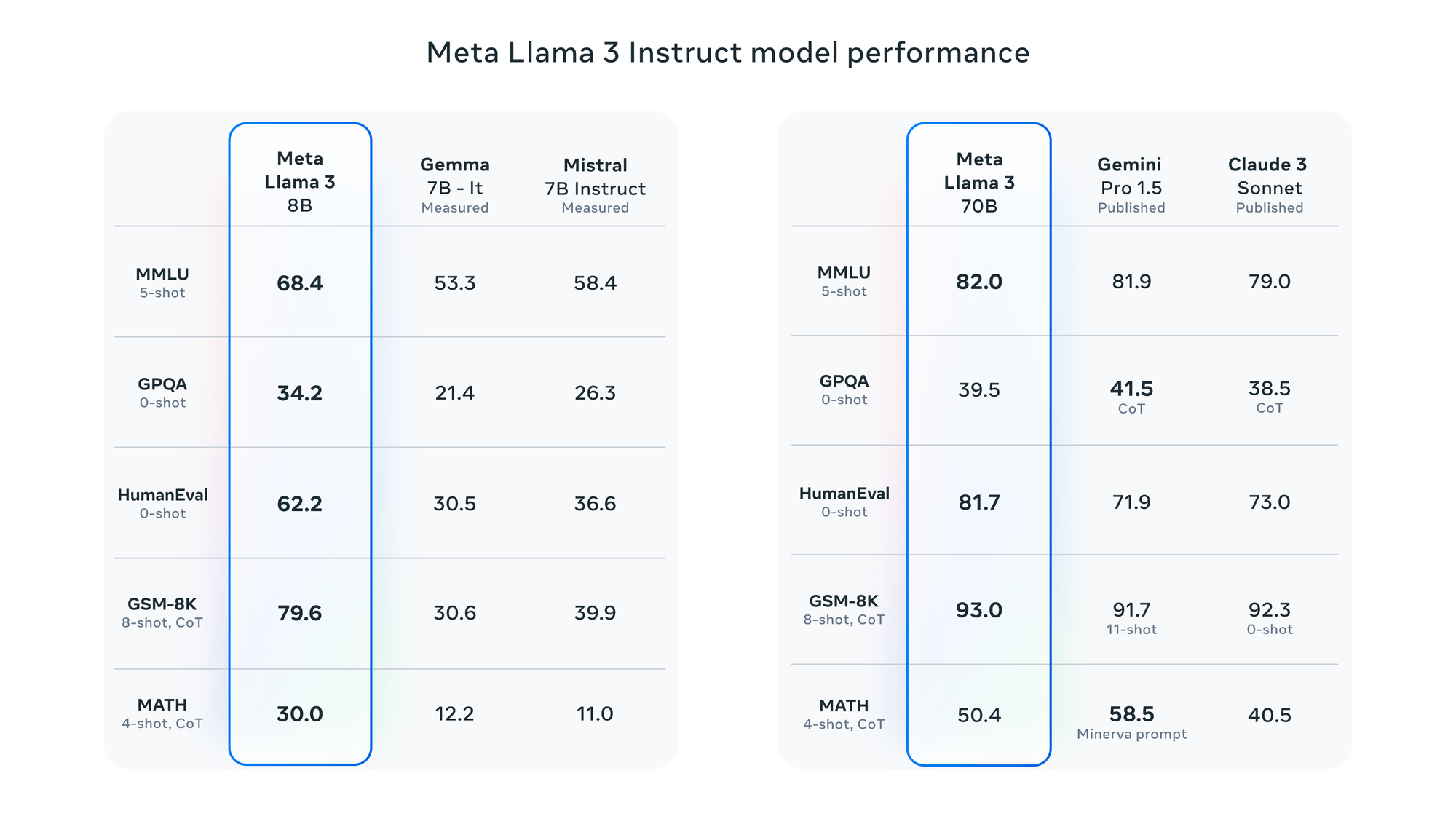
The models were also subject to a human preference ranking-based evaluation taking into consideration the responses from a custom 1,800 prompt collection covering 12 use cases, including asking for advice, brainstorming, classification, closed question answering, coding, creative writing, extraction, inhabiting a character/persona, open question answering, reasoning, rewriting, and summarization. The evaluation set was kept from Meta's modeling teams to avoid overfitting, so the results can be confidently taken to reflect Llama 3 70B's strong performance. The pre-trained variants of the Meta Llama 3 models were also benchmarked with very similar results, except here, the 70B model sets a new performance standard, and the 8B displays only the slightest variations in performance compared to Gemma and Mistral.
Meta attributes its groundbreaking results with the Llama 3 models to key innovations in the model architecture, training data, pre-training scaling, and instruction fine-tuning. The Meta Llama 3 architecture uses a 128K-token vocabulary tokenizer for efficient language encoding, and the models were trained using 8,192-token sequences with a mask to keep self-attention from crossing document boundaries. Additionally, the Meta Llama 3 pre-training leveraged over 15T publicly available tokens that conform to a dataset seven times larger than the one used to train Llama 2. The dataset underwent several data filtration pipelines, including heuristic filters, NSFW filters, semantic deduplication approaches, and text classifiers. The latter were trained using Llama 2 models once these were found to excel at identifying high-quality data. The development of the dataset also involved experimenting with different ways to mix the data to ensure an appropriate mixture that would preserve accuracy over specific use cases, such as trivia questions, STEM, coding, and historical knowledge. To prepare for multilingual reasoning, 5% of the dataset is not in English and covers over 30 languages. However, the models' multilingual performance is still not comparable with the English one.
The effort put into scaling pre-training was essential in making the most of a carefully curated training dataset. This was achieved by developing detailed scaling laws for downstream benchmark evaluations that allowed the research team to predict the performance of larger models on key tasks (code generation for the HumanEval benchmark, for example) before training to ensure that the final models would be performant on these same tasks across a variety of contexts and use cases. Moreover, the largest Meta Llama 3 models were trained using three different types of parallelization: data, model, and pipeline. The most efficient implementation of this method achieves a compute utilization of 400 TFLOPS per GPU when trained on 16K GPUs simultaneously. Together with other improvements, this resulted in an overall effective training time of over 95%, or a three-fold increase in training efficiency compared to Llama 2.
Finally, an essential step to deliver high-performing models optimized for chat-use cases was the innovative instruction fine-tuning that combines supervised fine-tuning (SFT), rejection sampling, proximal policy optimization (PPO), and direct policy optimization (DPO). More specifically, the prompts and preference rating quality vastly affected the performance of the aligned models. For instance, high-quality preference rankings in PPO and DPO deliver improved performance in coding tasks where the models struggle to select but not to reason to the correct answer. Learning from preference rankings enables models to take the final step and select the correct answer.
Meta has made certain to release the Meta Llama 3 8B and 70B responsibly by handing developers the additional tools needed to build safely with the models and following the necessary processes to ensure model outputs have undergone risk mitigation procedures. The release of the Meta Llama 3 models is joined by the availability of the new Llama Guard 2 and Cybersec Eval 2 versions, and Code Shield, a guardrail meant to filter out insecure code at inference time. Since Llama 3 was co-developed with torchtune, the library is integrated into the most popular LLM platforms such as Hugging Face, Weights & Biases, and EleutherAI, and torchtune also supports Executorch to enable efficient inference on mobile and edge devices, Llama 3 will truly be everywhere.
As a final note, Meta has revealed that its current largest model is over 400B parameters and is still in training. However, a snapshot of the model's performance showcases how it is trending, and sets the stage for the future steps announced by the company. Meta plans to release multimodal and multilingual models featuring larger context windows and improved core capabilities in the coming months.
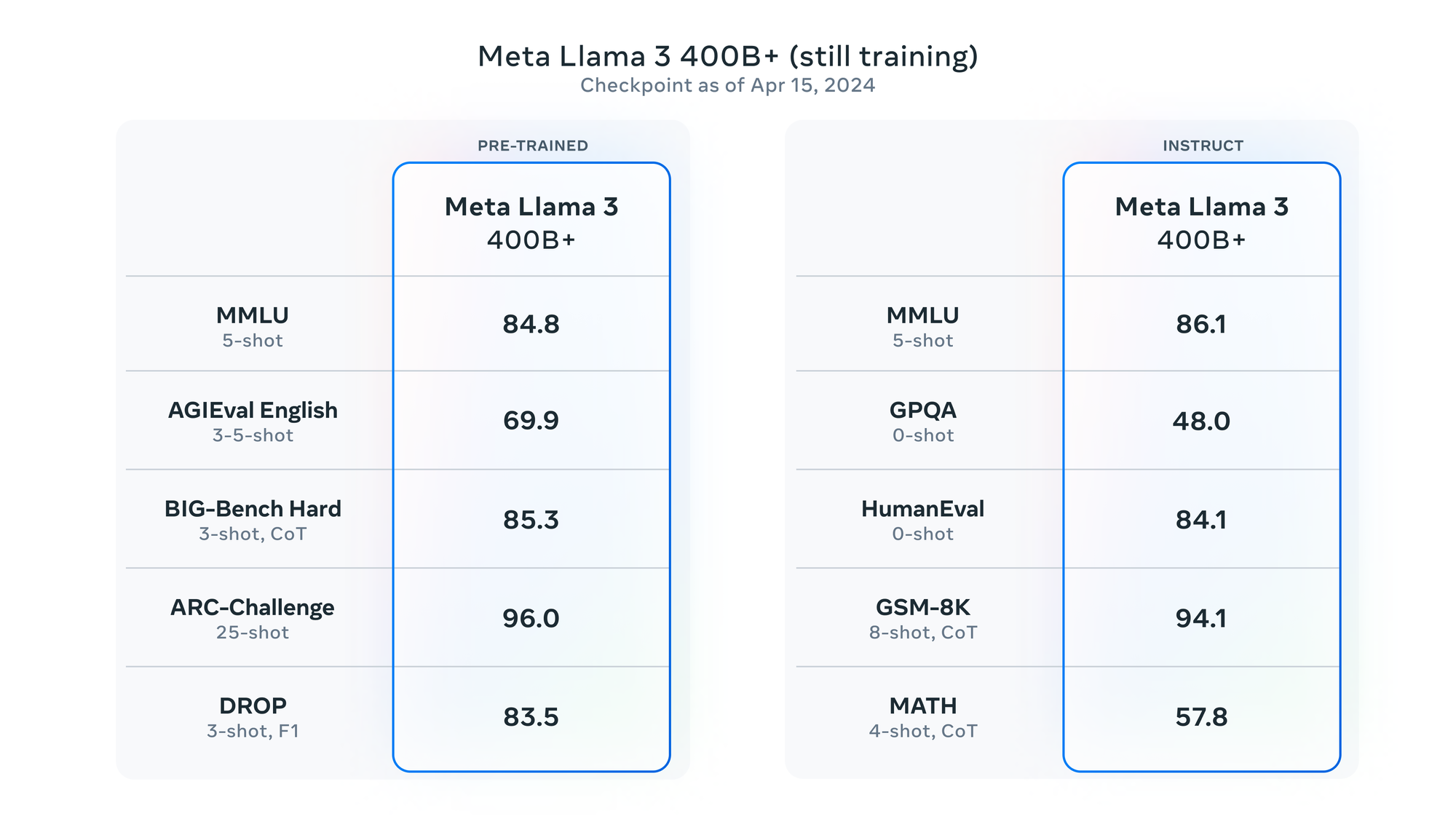
Although the 400B model's capabilities are not publicly available, those interested can start experimenting with Meta AI on Facebook, Instagram, WhatsApp, Messenger, and the web. (Disclaimer: Meta AI does not seem available outside the US yet.) The models will also be available on the most popular cloud, hosting, and hardware platforms, including the upcoming Ray-Ban Meta smart glasses.





Comments