
Last week, xAI released the Grok 3 models, complete with reasoning capabilities and a report-making research assistant agent called DeepSearch. According to xAI's announcement, the Grok 3 models were trained on the company's Colossus supercluster using ten times as much computing power as was used to train previous state-of-the-art models. Accordingly, the model is said to display improvements in reasoning, mathematics, coding, world knowledge, and instruction-following compared to its predecessor. Grok 3 is joined by Grok 3 mini, which sacrifices some accuracy to accommodate cost-efficient reasoning.
Reasoning capabilities and Grok's very first agent
Both models include a 'Think' mode, which activates their 'reasoning' capabilities and enables the models to spend more time refining their problem-solving strategies by fixing mistakes or simplifying previously adopted steps. Some sources have reported on a 'Big Brain' mode, which gives the models even more resources to tackle even more complex queries. The 'Think' and 'Big Brain' modes are reminiscent of OpenAI's settings for its o series models.
In parallel with Grok 3's reasoning capabilities, xAI proved it is keen to enter the 'agentic' AI era with the release of DeepSearch, an AI agent "built to relentlessly seek the truth across the entire corpus of human knowledge." According to xAI, DeepSearch is capable of everything from providing detailed analysis of current news and dishing out advice about one's "social woes" to conducting "in-depth scientific research". Like other similar products, DeepSearch performs detailed analysis on resources available online, and organizes its findings in downloadable reports with citations.
Grok 3 was available for X Premium and Premium+ from launch, with the latter also gaining access to the 'Think' and 'DeepSearch' capabilities. xAI has stated that even if it plans to roll out Grok 3's capabilities to all the chatbot's users, X Premium+ subscribers will enjoy higher usage limits and exclusive access to 'advanced capabilities'. Currently, the 'Think' and 'DeepSearch' capabilities can be trialed from the Grok web experience, at least.
Misleading benchmarks
As with every model launch, xAI reported on several benchmark results to back its claims about Grok 3's performance. These include Grok 3's maximum reached score on the Chatbot Arena leaderboard, which tests user preference; at the time of writing the model, codenamed chocolate (Early Grok-3), still tops the Overall leaderboard with a score of 1403. The company also reported on Grok 3's benchmark results with the 'Think' feature turned off, noting that it attains higher scores than models like GPT 4o, Gemini 2.0 Pro, DeepSeek V3, and Claude 3.5 Sonnet, in popular evaluations such as GPQA, MMLU-pro and MMMU.
Additionally, since competition mathematics has become the go-to test for "reasoning" models, xAI proudly reported that both Grok 3 and Grok 3 mini seemingly surpass OpenAI's o3 at the benchmark based on this year's American Invitational Mathematics Exam (AIME 2025), released on February 12. However, the reported highest scores for Grok 3 and Grok 3 mini—93.3 and 90.8, respectively—were the result of a technique called "cons@64", or "consensus at 64", where models are given 64 tries at answering a problem and the response appearing more frequently is taken as correct.
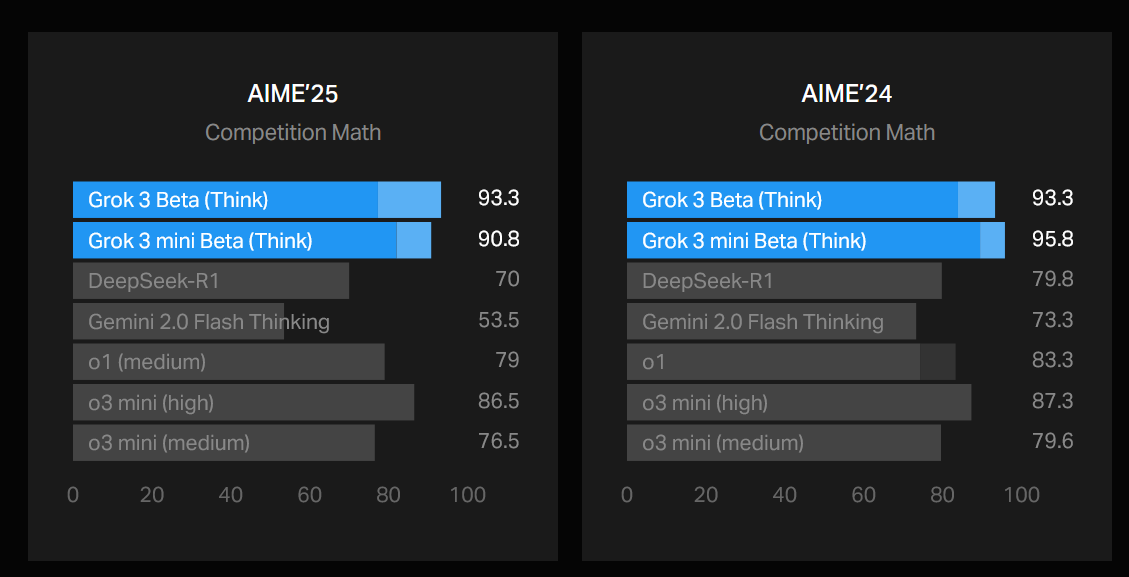
An OpenAI employee noted in an X post that these scores were being compared to o3 mini (high)'s reported score on the MathArena of 86.6 (by averaging the AIME 2025 I and II scores). The issue here is that MathArena scores are obtained using the pass@1 technique, which basically means the model only has one chance to answer the question correctly. xAI does report pass@1 scores for the Grok 3 models in its announcement, and at 77.3 (Grok 3) and 82 (Grok 3 mini), they still trail behind o3 mini (high). Thus, it seems that comparing cons@64 to pass@1 scores is not the fairest comparison, but one that could make Grok 3 seem more capable than it is.
xAI co-founder Igor Babuschkin defended that xAI were replicating OpenAI's strategy. This does not seem altogether accurate, since OpenAI was trying to prove an entirely different point: the company used both techniques to show that o3 mini (high) using pass@1 outperforms o1 (medium) even when the latter is given the advantage of being evaluated by its cons@64 scores.
Ultimately, other participants in the discussion pointed out that unless rarely mentioned variables like the available compute budget are also accounted for, benchmark score comparisons cannot be called fair in a substantive sense. It seems like in addition to bringing some additional controversy to an already heated race, this debate ended up perfectly exemplifying one of the reasons why benchmarks aren't the most appropriate evaluation mechanism.





Comments