
The YOLO (You Only Look Once) family of computer vision models is a neural network that predicts the position of bounding rectangles and classification probabilities for an image in one pass. In simple words, it is a method for identifying and recognizing objects in photographs in real-time.
The model became widely known after its developers, Joseph Redmon, Santosh Divvala, Ross Girshik and Ali Farhadi, presented the new architecture at the CVPR Computer Vision and Pattern Recognition Conference in 2016, and even won the OpenCV People Choice Awards for it.
But where did YOLO come from, what is its novelty, and why are there so many versions?
The original YOLO (You Only Look Once) was written by Joseph Redmon in a custom framework called Darknet.
Darknet is a very flexible research framework written in low-level languages that has produced a series of the best real-time object detectors in computer vision: YOLO, YOLOv2, YOLOv3, YOLOv4, YOLOv5, YOLOV6, YOLOV7 and now YOLOV8.
YOLO was the first object detection network to combine the task of bounding box drawing and class label identification into one end-to-end differentiable network.
Deep learning-based detection methods can be grouped into two stages: the first is called two-stage detection algorithms that make multiple-stage predictions, including networks such as RCNN, Fast-RCNN Fast-RCNN and others, the second class of detectors is called one-stage detectors such as SSD, EfficientDet and our YOLO.
Although YOLO is not the only one-step detection model, it is generally more efficient than the others in terms of speed and accuracy. After all, if you look at the detection problem as a one-step regression approach for determining the bounding box, YOLO models are often very fast and very small, making them faster to learn and easier to deploy, especially on devices with limited computing resources.
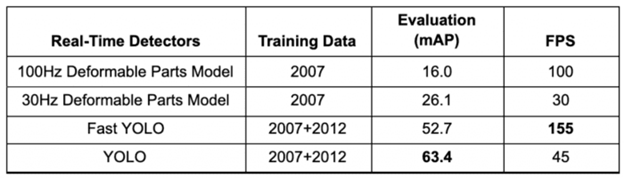
The basic YOLO model predicts images at 45 frames per second (FPS) on a Titan X GPU. The authors also developed a much lighter version of YOLO called Fast YOLO, which has fewer layers that process images at 155 frames per second.
Thus, YOLO achieved 63.4 mAP (average accuracy), more than double that of other real-time detectors, making it even more special. Both YOLO and Fast YOLO outperform the DPM real-time object detector variants by a significant margin in average accuracy (almost twice as much) and FPS.
YOLOv2
After its first introduction in 2016, the YOLO family of models continues to evolve each year. For example, the following year the YOLOv2 was released receiving an honorable mention at CVPR 2017. A number of iterative improvements were made to the architecture on top of YOLO, including BatchNorm, higher resolution and anchor boxes.
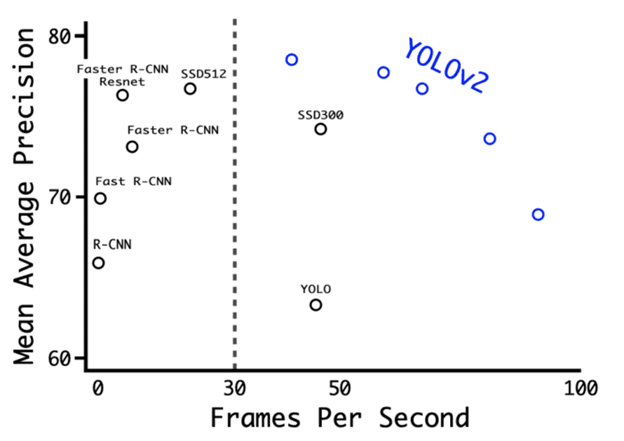
The improved YOLOv2 used a variety of new techniques to outperform current methods such as Faster-RCNN and SSD in both speed and accuracy. One such technique was multiscale learning, which allowed the network to predict at different input data sizes, allowing a tradeoff between speed and accuracy.
At 416×416 input data resolution, YOLOv2 achieved 76.8 mAP on the VOC 2007 dataset and 67 FPS on the Titan X GPU. On the same 544×544 dataset, YOLOv2 achieved 78.6 mAP and 40 FPS.
YOLOv3
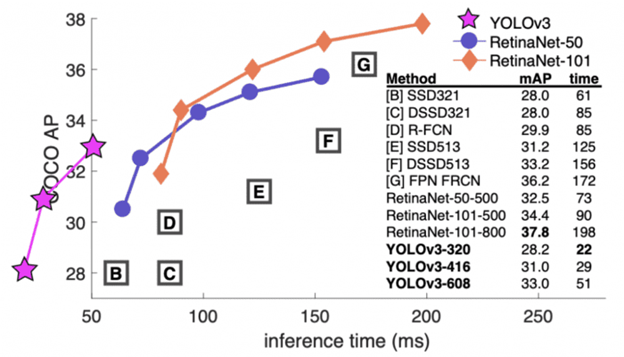
Here, developers Redmon and Farhadi released YOLOv3 in 2018, which builds on previous models by adding objectivity estimation to bounding box predictions, adding connections to layers of the reference network, and making predictions at three separate levels of detail to improve performance on small objects.
It is trained on different image resolutions such as 320×320, 416×416. At 320×320 resolution, YOLOv3 achieves 28.2 mAP at 45 FPS on a Titan X GPU and has the same accuracy as Single-Shot Detector (SSD321), but 3 times faster.
After YOLOv3 came out, Joseph Redmon stepped away from research in computer vision. Then researcher Alexey Bochkovsky and innovators such as Glenn Jocher began to open source their advances in computer vision.
YOLOv4
In April 2020, Alexey Bochkovsky released YOLOv4. This was his first work in the "YOLO family" that was not authored by Joseph Redmon. YOLOv4 is the product of much experimentation and research, combining various small new techniques to improve the accuracy and speed of the convolutional neural network.
In this paper, extensive experiments on different GPU architectures have been conducted and have shown that YOLOv4 outperforms all other object detection network architectures in terms of speed and accuracy.
YOLOv5
YOLOv5 was released in June 2020 just two months after YOLOv4, by Glenn Jocher and it, in turn, is the first model in the "YOLO family" that has not been released with an accompanying document and is therefore under "ongoing development" in the repository. This caused some controversy at first, but that notion was soon shattered as its capabilities were undermined by noise.
YOLOv5 offers a family of object detection architectures pre-trained on the MS COCO dataset. It was followed by the release of EfficientDet and YOLOv4. Today, the model is one of the official state-of-the-art models with tremendous support and easier use in production.
Version 5 is natively implemented in PyTorch, removing the limitations of the Darknet framework (based on the C programming language and not built in terms of production environments).
PP-YOLO
In August 2020, Baidu released PP-YOLO, which outperformed YOLOv4 on the COCO dataset. PP" stands for "PaddlePaddle," Baidu's neural networking framework (similar to Google's TensorFlow). PP-YOLO notes improved performance by taking advantage of substituted enhancements such as model foundation, DropBlock regularization, Matrix NMS, etc.
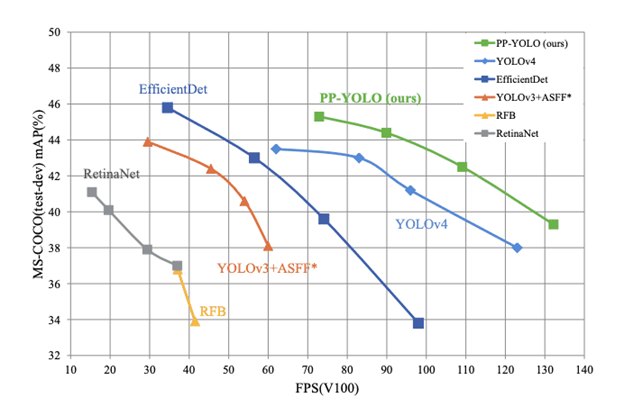
Comparison of the proposed PP-YOLO with other state-of-the-art object detectors. PP-YOLO runs faster (x-axis) than YOLOv4 and improves mAP (y-axis) from 43.5% to 45.2%.
PP-YOLOv2
The Baidu team authored this version again, releasing it in April 2021. PP-YOLOv2 made minor changes to PP-YOLO to improve performance, including the addition of mish activation and Path Aggregation Network.
YOLOv5-v6.0
YOLOv5-v6.0 was released in October 2021, including many new features and fixes (465 PRs from 73 contributors), making changes to the architecture, and introducing new P5 and P6 Nano models: YOLOv5n and YOLOv5n6. The Nano models have ~75% fewer parameters, from 7.5M to 1.9M, than previous models, small enough to run on mobile and CPUs. YOLOv5 outperforms the EfficientDet variants by a significant margin. Moreover, even the smallest YOLOv5 variant (i.e., YOLOv5n6) achieves comparable accuracy much faster than EfficientDet.
YOLOv6
Released as early as 2022, YOLOv6 is an iteration of the YOLO trunk and neck, redesigning them with hardware in mind - introducing what they call the EfficientRep Backbone and Rep-PAN Neck. In YOLO models up to and including YOLOv5, the classification and box-regression heads use the same features. In YOLOv6, the heads are separated, that is, the network has additional layers separating these features from the final head, which has empirically shown to increase performance.
The YOLOv6 model simulates the COCO data set more accurately than YOLOv5 at a comparable output rate. This was tested on a Tesla V100 GPU.
YOLOv7
Finally, YOLOv7, available in July 2022, is the latest cutting-edge object detector in the YOLO family. The version is currently considered the fastest and most accurate real-time object detector. This model contains all the most advanced deep neural network training techniques.
In YOLOv7, the authors build on the research that has been done on this topic, taking into account the amount of memory needed to store the layers in memory, and the distance it takes for the gradient to propagate back through the layers - the shorter the gradient, the more powerful the network will be able to learn. The last layer aggregation they chose was E-ELAN, an extended version of the ELAN compute unit.
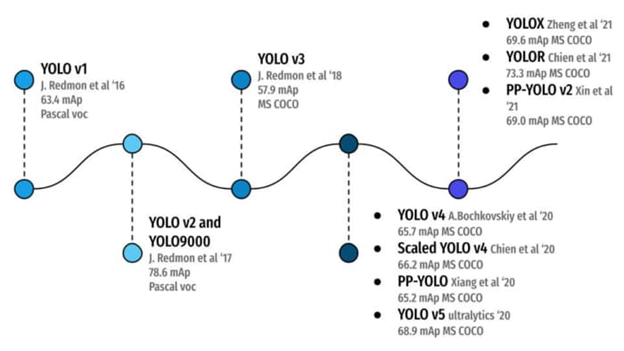
YOLO has progressed every year, from a result of 63.4 mAP on the Pascal VOC dataset (20 classes) in 2016 to YOLOR in 2021 with a result of 73.3 mAP on the much more complex MS COCO dataset (80 classes). Therein lies the beauty of this invention. Through constant hard work and resilience, the YOLO object detection system has come a long and successful way!
YOLO v8
On January 10th, 2023, the latest YOLO version, YOLO8, launched. Ultralytics have developed YOLOv8. This cutting-edge, state-of-the-art model builds on the successes of prior YOLO versions and incorporates new advancements to enhance its performance and versatility.
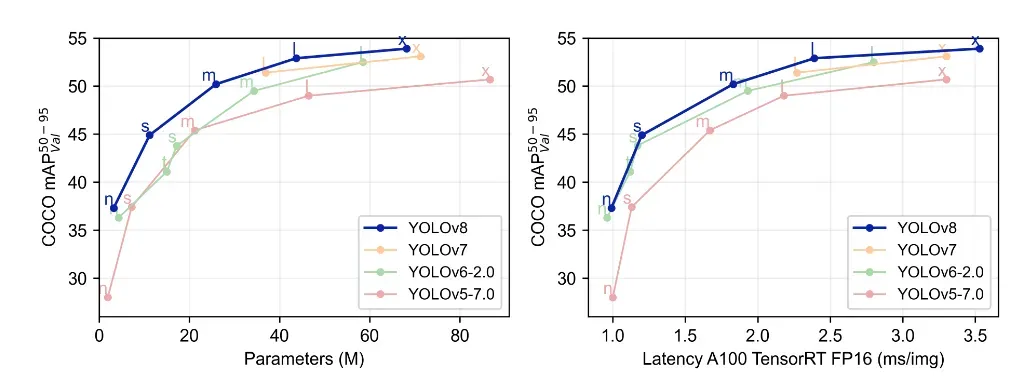
One of YOLOv8's key strengths is its versatility. As a framework that supports all previous YOLO models, it is easy for users to switch between different versions and evaluate their performance, making it a great choice for those who want to utilize the latest YOLO technology while still being able to utilize their older models.
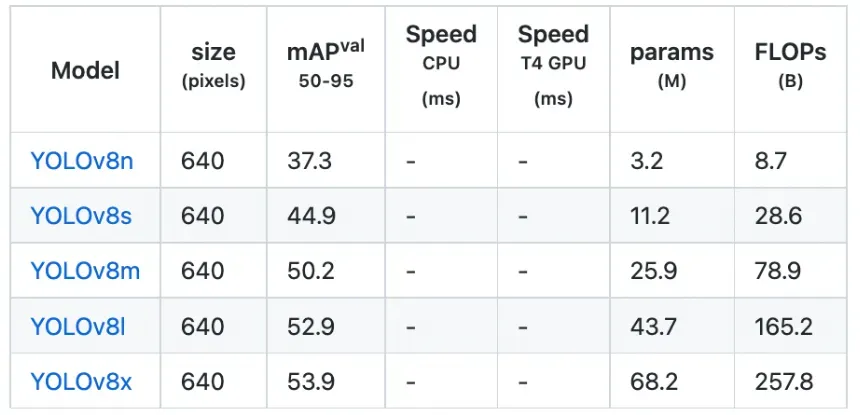
Along with its versatility, YOLOv8 boasts several other innovations that make it a strong candidate for a wide range of object detection and image segmentation tasks. These include a new backbone network, anchor-free detection head, and loss function. Additionally, YOLOv8 is highly efficient and can run on a variety of hardware, from CPUs to GPUs.
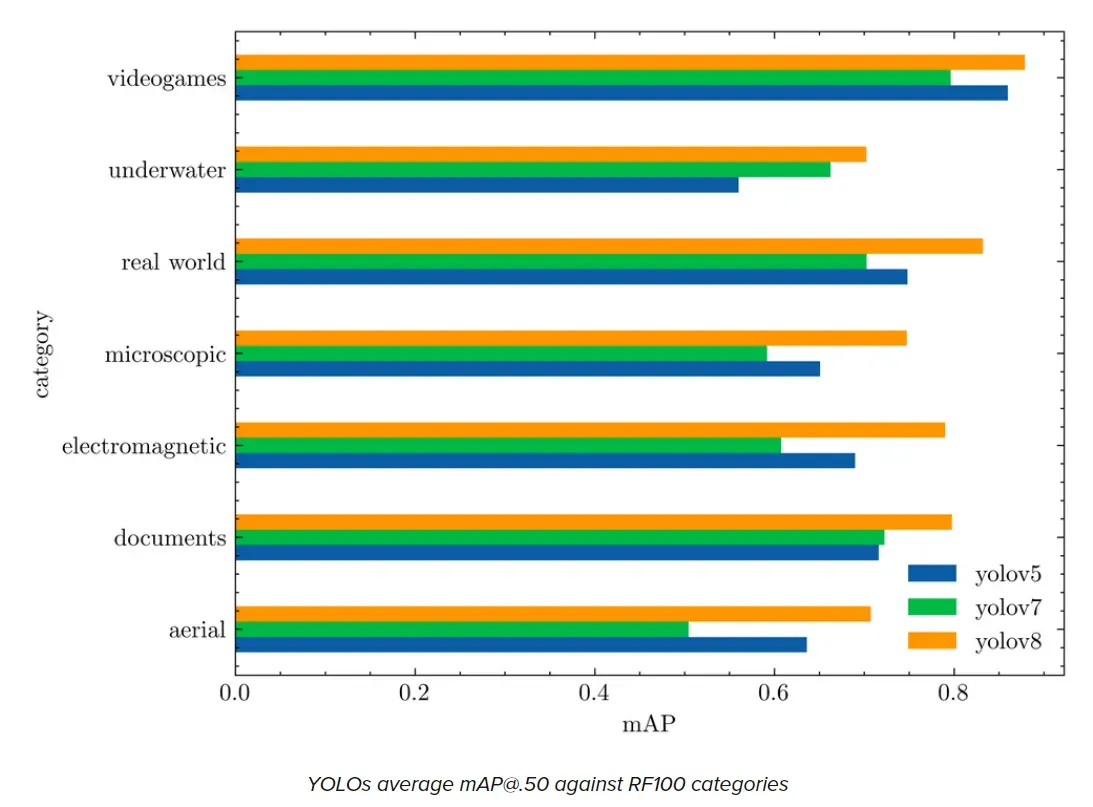
In conclusion, YOLOv8 is a robust and adaptable tool for object detection and image segmentation that offers the best of both worlds: the latest state-of-the-art technology and the ability to utilize and compare all previous YOLO versions.





Comments