
Adept, the company building a machine learning model that can interact with every software, API, and website available on a computer, has released a small-scale version of the multimodal model behind its product, Fuyu-8B. The base model is available at HuggingFace and was released with a Creative Commons CC-BY-NC license, making it permissible for all uses. The release comes just over a month after Adept released Persimmon-8B, an abbreviated version of its proprietary language model with an open Apache license.
One of the most noteworthy features of Fuyu-8B is that, unlike other multimodal models, it lacks an image encoder. Many multimodal models are connected to an image encoder trained separately from the language model. The encoder is trained on images that it transforms into an appropriate output that the language model can understand. Then, the image encoder and text decoder will be trained together on low-resolution images before optionally undergoing additional hi-resolution training that further extends the model's capacity. Because this is a multi-step affair, both training and scaling these models are often complicated.
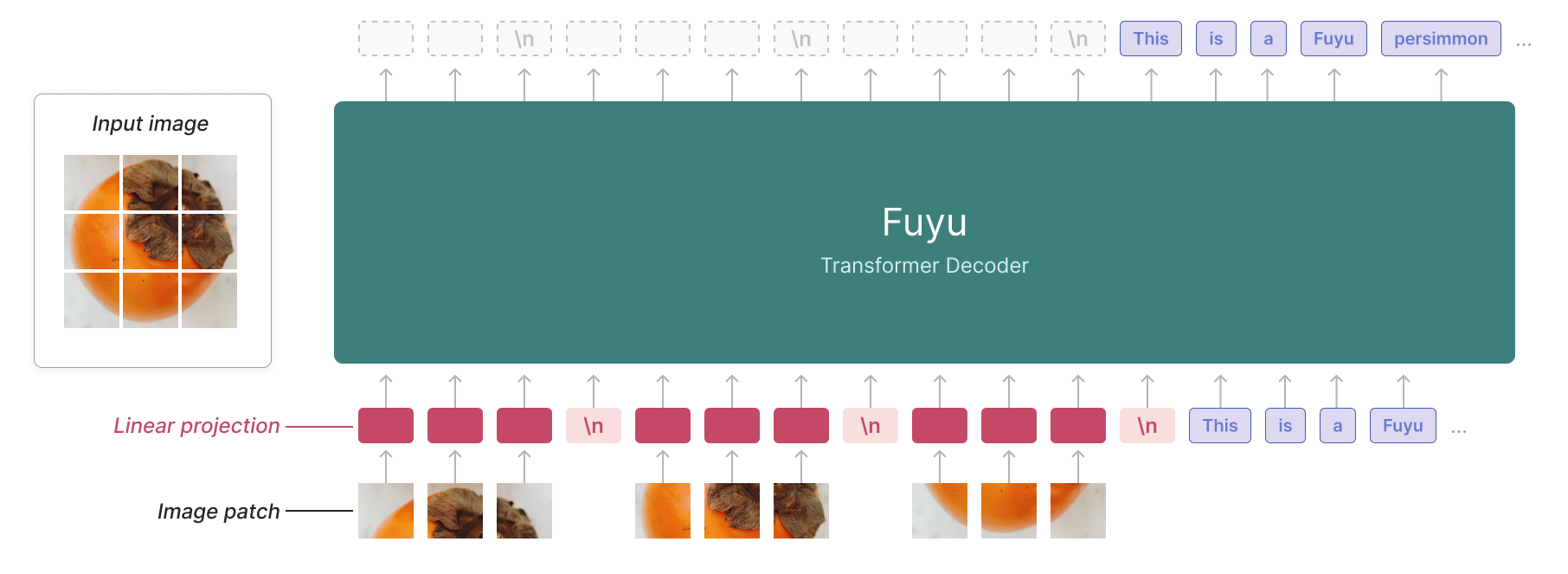
Fuyu-8B bypasses the encoding stage and processes the images directly through its decoder to simplify the whole training and scaling process. The pictures are broken up into pieces and linearly fed to the decoder. A unique image-newline character signals the relevant line breaks in the picture to the decoder. Besides simplifying the process and speeding things up, bypassing the encoder means the model can be trained with images of varying resolutions simultaneously.
The team at Adept tested Fuyu against PALM-e, PALI-X, QWEN-VL, and LLaVA 1.5 using popular image-understanding and image-captioning benchmarks. One of the most outstanding features of the results is not the numbers that show that Fuyu is a competitive model but rather that the reference answers penalized Fuyu for being too accurate. When presented with an image of a bear playing a snare, the OKVQA benchmark expects the answer drum. Thus, Fuyu scored a 0 for allegedly identifying the instrument incorrectly as a snare. Likewise, when given a picture of Big Ben at nighttime as input, the CIDEr reference captions do not include any reference to Big Ben. As a result, Fuyu is penalized for correctly captioning the image with the phrase A nighttime view of Big Ben and the Houses of Parliament.
Fuyu-8B's announcement includes a variety of examples that showcase the model's capabilities. These go from charts and document understanding, being able to interpret scientific diagrams, to the (upcoming) ability to perform OCR on images and perform localization and QA tasks. Undoubtedly, Fuyu-8B has the potential to be put to impressive applications, and it is a truly enticing sneak peek into the capabilities of the full-sized model that powers Adept's platform.





Comments