
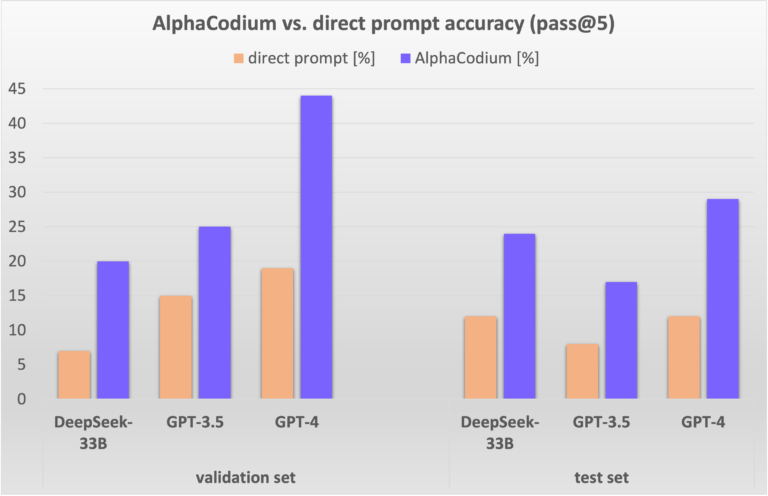
CodiumAI has introduced AlphaCodium, a new code generation flow meant to improve the performance of pre-trained LLMs when solving code problems without fine-tuning. Unlike approaches to code problem-solving relying on costly, time-consuming, and data-hungry training phases to achieve their results, AlphaCodium favors the development of an iterative, test-based, multi-stage flow that results in improved performance with a reduced computational footprint. AlphaCodium was tested against a code generation dataset known as CodeContests, which consists of a selection of code generation problems sourced from platforms such as Codeforces. One of the main results shows an increase in performance for GPT-4 (pass@5): from 19% when evaluated using a single direct prompt to 44% accuracy when using the AlphaCodium Flow.
The flow is model-agnostic and can be used with closed and open-source models, with improvements being the case for all the models evaluated. GPT-3.5 increased its accuracy from around 17 to 25%, whereas DeepSeek saw an increase from around 5% to 20% when evaluated concerning the validation set.
AlphaCodium's performance with GPT-4 was also compared to AlphaCode and AlphaCode 2, with AlphaCodium showing a performance comparable to AlphaCode, which is based on fine-tuned transformer-based models and requires four orders of magnitude more LLM calls than AlphaCodium. This shows an impressive delivery of performance at a reduced computational cost.
Each CodeContests problem is composed of a description and a set of public tests, which are available as inputs for the model. The goal is to develop an algorithmic solution that provides a valid output for any valid input. Along with the public tests, an undisclosed set of private tests is used to evaluate the models' solutions to each problem. Rather than attempting to come up with a general solution directly, AlphaCodium attempts to solve the public cases first. This is done by first reflecting on the problem to identify easily overlooked details such as possible inputs, outputs, and restraints. Then, after solving the public cases and explaining why each input leads to the corresponding output, AlphaCodium sketches two or three attempts at general solutions.
In the next stage, AlphaCodium ranks the solutions to find the most plausible candidate and then generates additional tests that cover several possible inputs. At this point, a code solution is generated and tested against a selection of the public and AI-generated tests. Once the tests pass or the try limit is reached, AlphaCode iterates the base code against the public tests and attempts to fix errors if any are encountered. Finally, it repeats the iteration process against the AI-generated tests in a process known as double validation.
Perhaps the most notable departure from closed-source solutions such as AlphaCode is that AlphaCodium was released with reproducible code and an evaluation script, two features enabling reliable and reproducible future comparisons. This can be contrasted with the case of AlphaCode 2, where the technical paper reports results on a CodeContests benchmark for an unreleased updated variant. Thus, although AlphaCode 2 is known to be "over 10000× more sample efficient" than its predecessor, this is an estimated comparison, rather than a reproducible one.





Comments