
On Monday, Anthropic released Claude 3.7 Sonnet, a model the company has called "the first hybrid reasoning model on the market" because it lets users choose whether to turn its "reasoning" capabilities on or prefer a faster response. API users can also determine how long they want Claude 3.7 Sonnet to think for by specifying an upper limit on the number of tokens Claude can use, up to its maximum supported length of 128K output tokens.
Hybrid Reasoning Approach
Anthropic claims Claude 3.7 Sonnet better models human reasoning because we use the same brain for complex reasoning and more immediate thoughts. On a more practical note, the company says that an important benefit of Claude 3.7 Sonnet is that it offers a more unified user experience. According to an X post by OpenAI CEO Sam Altman, OpenAI is looking to perform a similar maneuver by integrating o3 into GPT-5 rather than releasing the former as a standalone model.
Unlike OpenAI, Anthropic has saved itself from having to clarify confusions regarding model performance and capabilities. The press release puts it very simply: with its reasoning capabilities turned off, Claude 3.7 Sonnet should be seen as an improvement over Claude 3.5 Sonnet. Consequently, Claude 3.7 Sonnet's "reasoning" capabilities are simply an additional boost that improves the model's performance on tasks including math, physics, coding and instruction following.
Optimized for real-world business and coding tasks
According to the announcement, another key differentiator from other current foundation models is that Claude 3.7 Sonnet is intentionally less focused on competitive math and coding, with its capabilities redirected to real-world use cases, and especially those requiring tool use. These claims are consistent with the reported benchmark scores. In the AIME'24 benchmark, which has unexpectedly become a sort of golden standard for foundation models' math capabilities, Claude 3.7 Sonnet gets less than stellar results, falling behind OpenAI's o1 and o3 mini, DeepSeek's R1, and even the early Grok 3.
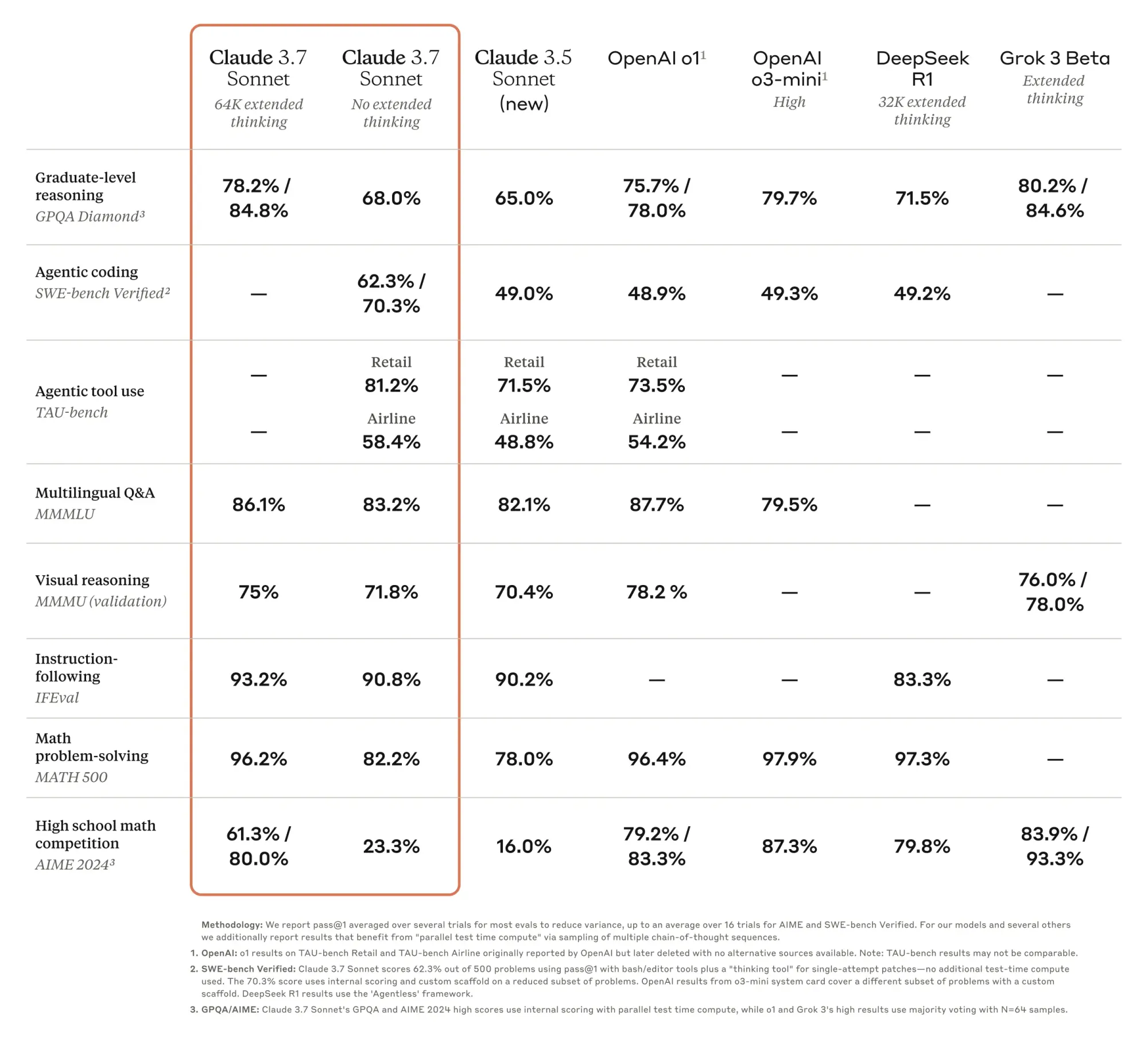
In contrast, Claude 3.7 Sonnet (without extended thinking capabilities) shines in the SWE-Bench Verified benchmark, designed to test models' capabilities for solving 'real-world' software issues, and in TAU-bench, an evaluation centered on tool use in customer service interactions with simulations in retail and airline domains. In addition, Anthropic highlighted that early testers including Cursor, Cognition, Vercel, Replit, and Canva confirmed the model's superior coding capabilities
For the reported TAU-bench scores of 81.2% (retail) and 58.4% (airline), Claude 3.7 Sonnet was granted access to a "planning" tool that encourages it to write down its "thoughts" as it completes a task trajectory. Anthropic claims this tool is different from Claude 3.7 Sonnet's extended thinking. The SWE-Bench Verified were calculated over a subset of 489 problems (out of 500) which are compatible with Anthropic's infrastructure. The highest reported score was achieved by providing Claude 3.7 Sonnet with a bash and a file editing tool.
Introducing Claude Code
Alongside the new model, Anthropic has launched Claude Code, an agentic command line tool available as a limited research preview. This tool enables developers to delegate substantial engineering tasks to Claude directly from their terminal.
Claude Code can:
- Search and read code
- Edit files
- Write and run tests
- Commit and push code to GitHub
- Use command line tools
Early testing has reportedly yielded significant time savings, with Claude Code easily completing tasks that would usually take humans 45 or more minutes of manual work. Anthropic has stated that the research preview will enable it to gather essential feedback on Claude Code. The company plans to keep improving the product by improving its reliability and adding new features like long-running command support.
In addition to releasing Claude Code, Anthropic has improved the coding experience by making the GitHub integration available across all Claude plans, free and paid. By connecting their repositories directly with Claude, developers can give Claude 3.7 Sonnet the best possible understanding of their projects, enabling the model to become an even better coding assistant.
Availability and Pricing
Claude 3.7 Sonnet is now available for all Claude users. The model is also available via the Anthropic API, Amazon Bedrock, and Google Cloud's Vertex AI. Claude users on the Free tier are the only users without access to Claude 3.7 Sonnet's extended thinking capabilities. Pricing for Claude 3.7 Sonnet remains unchanged compared to its predecessor's, and already includes thinking tokens. ($3 per million input tokens and $15 per million output tokens.)
Improved safety and reliability
Anthropic reports that Claude 3.7 Sonnet is better at telling apart benign and harmful requests, which translates to a 45% reduction in unnecessary refusals (situations in which Claude confuses a benign request for a harmful one). The model release includes a detailed model system card that describes Anthropic's Responsible Scaling Policy evaluations, details potential risks emerging from new features such as computer use, as well as the strategies used to mitigate them, and examines whether reasoning models could bring the benefit of improved understanding about their inner workings.





Comments