
Ray, Anyscale’s open-source unified compute framework that makes it easy to scale AI and Python workloads — from reinforcement learning to deep learning to tuning and model serving, has been updated to version 2.7. The release includes many new features, including the general release of Ray Serve, Ray Train, and KubeRay.
The blog post announcing the release highlights the following key features included in the update:
- Simplified APIs in Ray Train for general availability
- Stabilized and enhanced Ray Serve and KubeRay for general availability
- Introduced RayLLM -- LLM model serving on Ray Serve
- Stabilized Ray Data for an upcoming general availability
- Added initial Accelerator support for TPUs, Trainium, and Inferentia
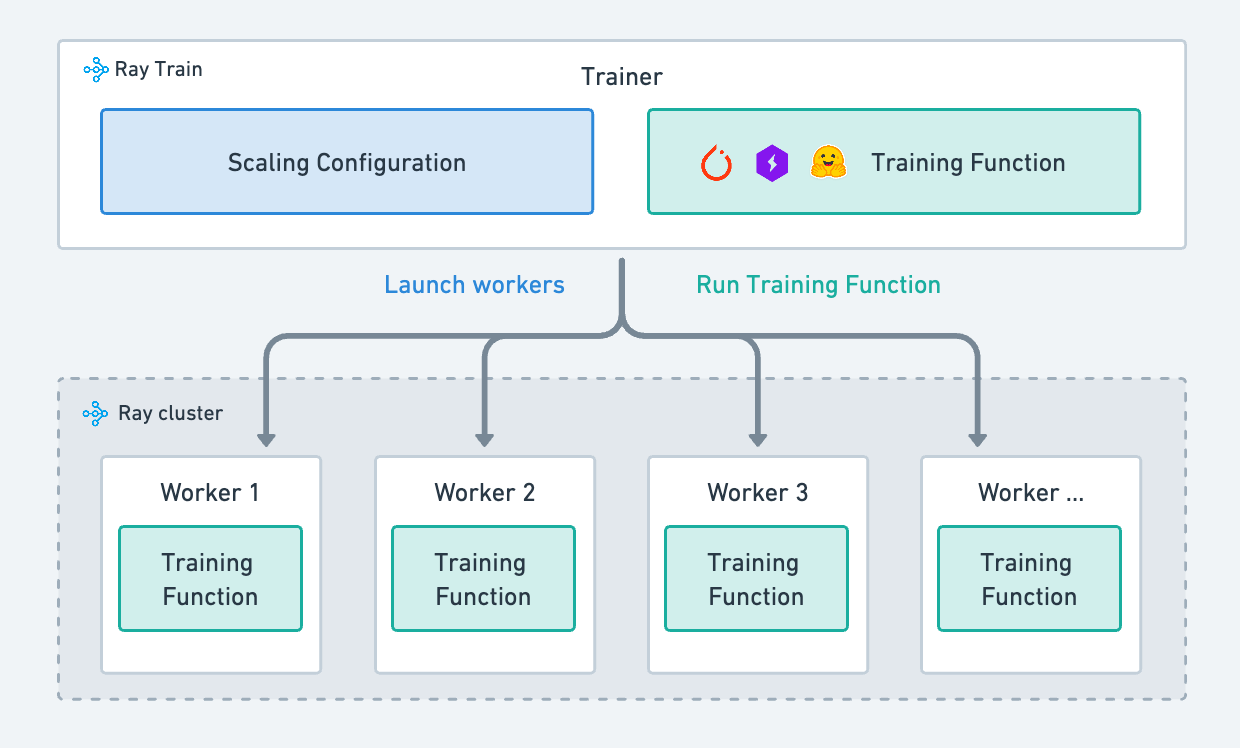
The concept “Ray AI Runtime” (Ray AIR, for short) is now being discontinued, with its components now simply known as Ray AI libraries. Thus, Ray Train is no longer part of Ray AIR, but simply a Ray-based library for distributed training. Moreover, several of the available trainers have now been consolidated into the TorchTrainer module. Several other concepts formerly available as part of Ray AIR have been moved over to RayTrain to reduce the modules needed for distributed training. RayTrain incorporates a new standard storage solution that depends on common public cloud storage and NFS, thus solving the difficulties experienced by users of non-standard storage solutions. Finally, Ray Train includes a host of new features to make the training and fine-tuning of LLMs easier.
Enhancements to Ray Serve and KubeRay include a high performant gRPC proxy, a new DeploymentHandle API, for unifying existing RayServeHandle and RayServeSyncHandle APIs, and Websocket with FastAPI support. Streaming is now supported in Ray Serve, allowing developers to share the results of their models incrementally. This is especially useful when dealing with text generation or video processing, where the completion of requests may take a long time. Finally, there is also batching Serve requests, model multiplexing, and multi-app support, with the documentation including all of the specifics and examples needed to implement these features.
Ray 2.7 release also marks the official launch of KubeRay 1.0 for general availability, after some major stability fixes and revisions in the documentation, which now includes user guides as examples of best practices.
Ray previously included an evaluation and serving solution for LLMs known as Aviary. This solution has been renamed as RayLLM, and in response to the demand for using Aviary to serve, rather than evaluate models, RayLLM is now primarily a LLM serving solution. Plans for RayLLM include configurations for the most popular open-source LLMs available, in addition to open-source library integration, including vLLM.
Improvements to Ray Data, Ray’s scalable data processing library for ML workloads, are all focused on performance, resulting in a 3.4x improvement in image batch inference benchmarks and a 6.5x improvement in training data ingestion benchmarks. Anyscale has promised continued memory efficiency and reliability improvements in preparation for general availability.
Finally, Ray Core now includes support for accelerator devices beyond GPUs. Support was extended to cover TPUs, Trainium, and Inferentia. This means developers will now be able to scale their applications in Google Cloud and AWS without the need for custom resources. Anyscale says they’ll keep working towards better accelerator integration to “enable seamless distributed training and model serving, along with support for more accelerators.”
Ray Core will automatically detect these resources instead of requiring custom resources, as follows:
@ray.remote(resources={"TPU": 4})
def train(config):
hf = init_hf(
model_name="llama2/2B",
dataset_name="wikitext")
return train_model(
training_args=config["training_args"],
data_args=config["data_args"],
trainer=config["trainer"],
train_dataset=config["train_dataset"])For TPUs, Anyscale have also integrated pod support to the TPU cluster launcher. You can find an example here.
With the release of Ray 2.7, Anyscale hopes to deliver a simple, stable and well-performing suite of solutions. The general availability of Ray AI Libraries and KubeRay is a step in the right direction, with the upcoming general availability plans for Ray Data confirming that Anyscale’s Ray will keep on moving forward.





Comments