
Arthur is proud to announce the release of their latest innovation, "Arthur Bench," an advanced evaluation tool designed to benchmark and compare large language models (LLMs) in various real-world scenarios. Following the successful launch of Arthur Shield in May, which serves as a safety barrier against risks associated with LLMs, Arthur Bench steps in to further support businesses in making informed decisions regarding AI integration.
Key Features and Benefits of Arthur Bench:
- Model Selection & Validation: With the AI landscape in constant flux, Arthur Bench provides a consistent metric for businesses to gauge the performance of various LLMs, ensuring that their chosen model aligns with specific operational needs.
- Budget & Privacy Optimization: Recognizing that advanced LLMs aren't always necessary, the tool aids in identifying cost-effective models without compromising performance. This feature is especially beneficial for tasks such as generating basic text responses, allowing businesses to optimize their AI budget. Furthermore, businesses can utilize certain models in-house, enhancing data privacy controls.
- Translating Academic Metrics into Practical Insights: Arthur Bench bridges the gap between academic benchmarks and real-world applications. It not only allows firms to assess LLMs based on standard metrics like fairness but also enables the creation of custom benchmarks that align with a company's unique objectives.
In tandem with Arthur Bench, the company has also launched the Generative Assessment Project (GAP), a research program aimed at evaluating and ranking LLMs from major industry players like OpenAI, Anthropic, and Meta. The aim of GAP is to shed light on the contrasting behaviors of various models and share best practices with the broader community.
Adam Wenchel, the CEO of Arthur, emphasized the importance of understanding the intricate performance nuances among LLMs. He said, "With Bench, we're offering an open-source platform for teams to delve deep into the distinctions between different LLM providers, their strategies, and custom training techniques."
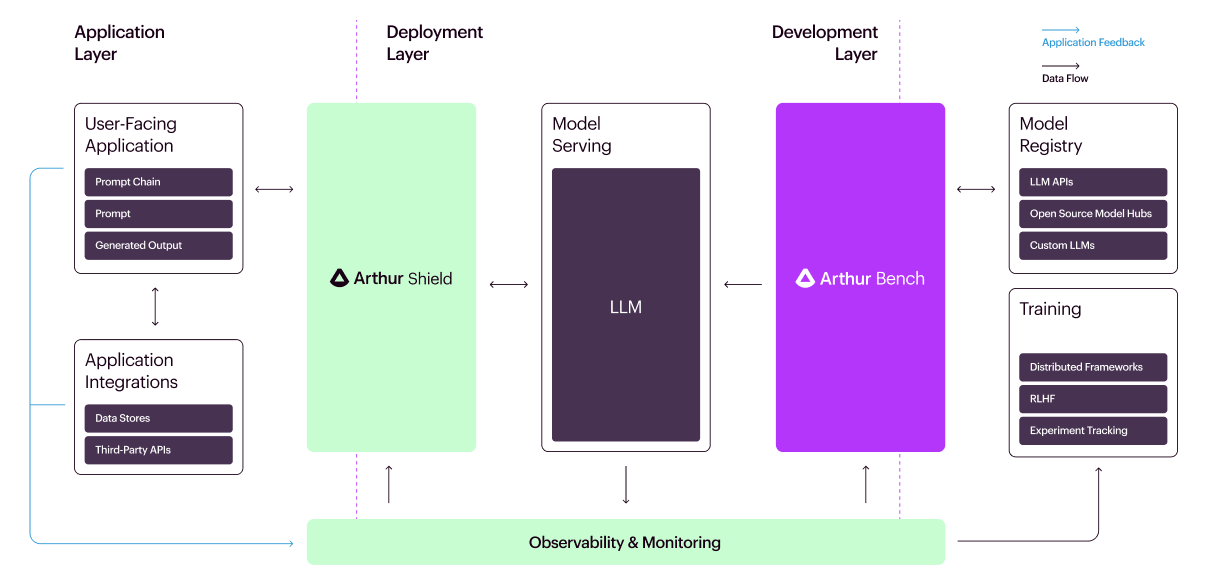
As an open-source platform, Arthur Bench will continually evolve, with new metrics and features being incorporated based on community feedback. Those interested can access more details on their GitHub repository or visit the official website.





Comments