
Welcome to this week's edition of Data Phoenix Digest! This newsletter keeps you up-to-date on the news in our community and summarizes the top research papers, articles, and news, to keep you track of trends in the Data & AI world!
Be active in our community and join our Slack to discuss the latest news of our community, top research papers, articles, events, jobs, and more...
Data Phoenix's upcoming webinars:

Gorilla: Large Language Model Connected with Massive APIs
The Gorilla project is designed to connect large language models (LLMs) with a wide range of services and applications exposed through APIs. Imagine if ChatGPT could interact with thousands of services, ranging from Instagram and Doordash to tools like Google Calendar and Stripe, to help you accomplish tasks. This may be how we interact with computers and even the web in the future. Gorilla is an LLM that we train using a concept we call retriever-aware training (RAT), which picks the right API to perform a task that a user can specify in natural language. Gorilla also introduces an Abstract Syntax Tree (AST) based sub-tree matching algorithm, which for the first time allows us to measure hallucination of LLMs!
Speaker: Shishir is a Ph.D. student in Computer Science at UC Berkeley advised by Joseph Gonzalez and Prabal Dutta affiliated with the Sky Computing Lab (previously RISE), Lab11, and Berkeley AI Research (BAIR). He is broadly interested in ML-Systems, and LLMs. Previously he has interned at Google Brain, and Amazon Science, and was at Microsoft Research as a Research Fellow before.
- Trends and Applications of AI/ML and Analytics in Sports
Rajesh Kumar (Assistant Professor, Woxsen University) / October 5 - Large Language Models for Program Synthesis
Xinyun Chen (Research Scientist at Google DeepMind) / October 16 - Lessons Learned from Building a Managed RAG Solution
Denys Linkov (ML Lead at Voiceflow) / October 19 - Using memory with LLM applications in production
Sergio Prada (Co-founder and CTO at Metal) / October 26 - MLOps for Ads Ranking at Pinterest
Aayush Mudgal (Senior ML Engineer at Pinterest) / October 31
DataPhoenix recommends:

Webinar "High-performance RAG with LlamaIndex"
Greg Loughnane and Chris Alexiuk from AI Makerspace will discuss how to use hierarchical embeddings to return relevant context from a large dataset, as measured by context precision and context recall via the RAG ASsessment framework, and also show the impact of fine-tuning the embedding model on retrieval metrics.
Summary of the top articles and papers
Articles
Zero-ETL, ChatGPT, And The Future of Data Engineering
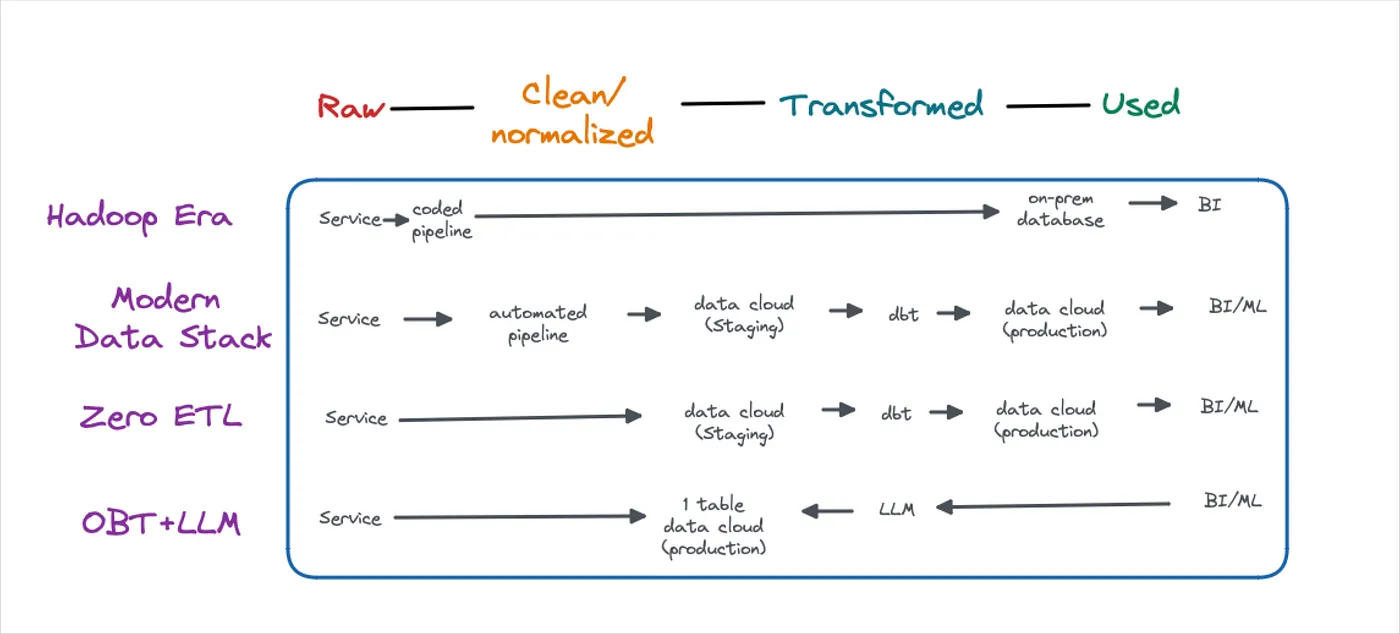
Today, data is generated by a service and written into a transactional DB. An automatic pipeline is deployed, which moves data to the analytical data warehouse and modifies it along the way. Zero-ETL and OBT-LLM change this ingestion process. Here’s how!
Using MLflow AI Gateway and Llama 2 to Build Generative AI Apps
MLflow AI Gateway is a highly scalable, enterprise-grade API gateway. In this article, you’ll learn how to build and deploy a RAG application on the Databricks Lakehouse AI platform using the Llama2-70B-Chat model and the Instructor-XL model.
Best Practices for Building Containers for Machine Learning
This article explores the best practices for building containers. Some of the practices are more general and relevant for any system using containers, while others are specific for machine learning workloads. Give it a read, or watch a video!
Building a Modern Machine Learning Platform with Ray
In this article, the author discusses how to build a modern ML platform by adopting Ray as its foundation. He walks through examples of using Ray’s ecosystem, including RayDP, Ray Tune, and Ray Serve to solve problems in this new infrastructure development.
5 Quick Tips to Improve Your MLflow Model Experimentation
This article discusses the use of MLflow in enhancing the development process of machine learning models. The focus is on its experimentation component that allows data scientists to log optimal algorithms and parameter combinations to speed up model iterations.
Papers & projects
LERF: Language Embedded Radiance Fields
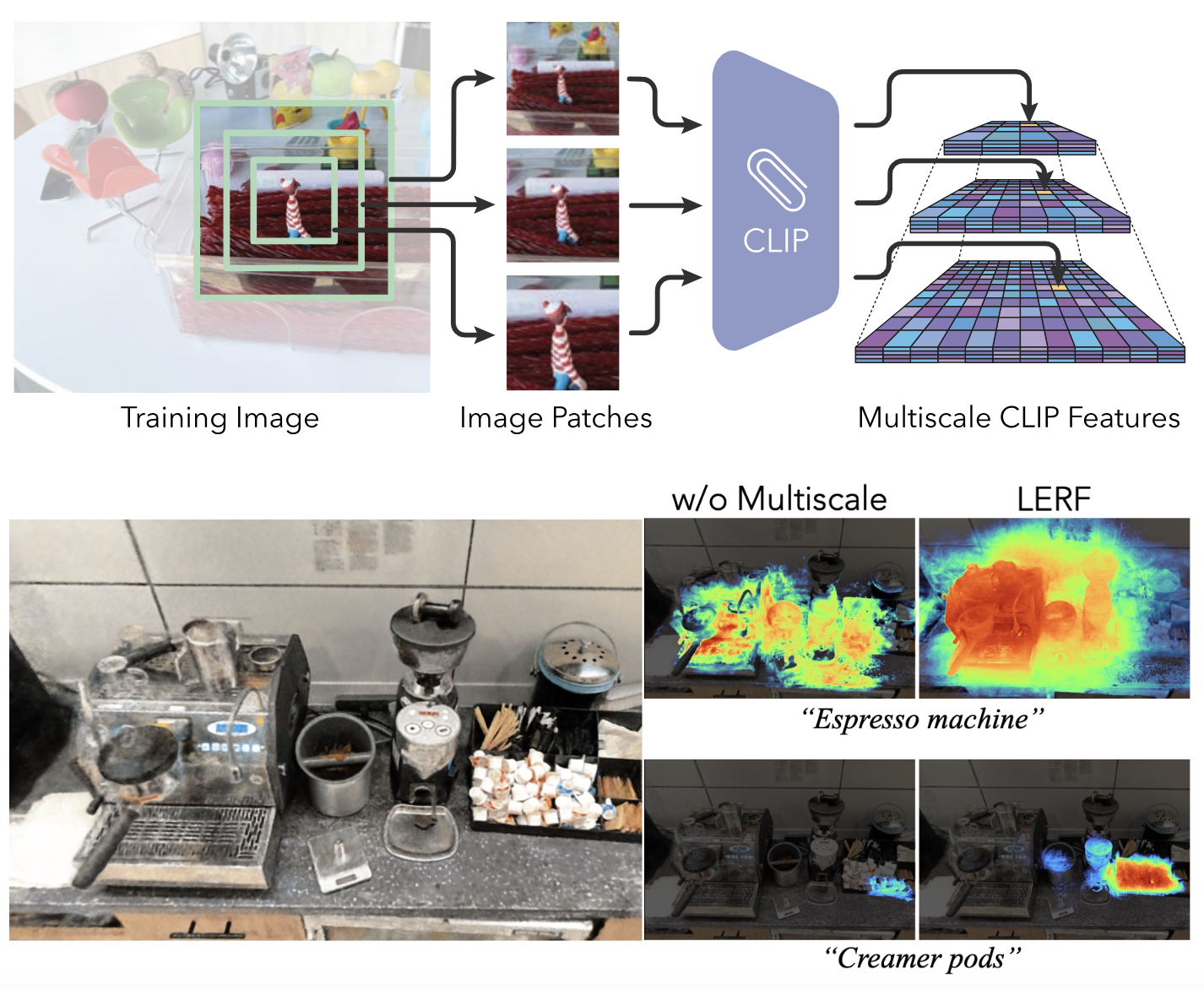
3D CLIP embeddings are more robust to occlusion and viewpoint changes than 2D CLIP ones. LERF optimizes a dense, multi-scale language 3D field by volume rendering CLIP embeddings along training rays, supervising embeddings with multi-scale CLIP features.
Tracking Anything with Decoupled Video Segmentation
DEVA is a decoupled video segmentation approach consisting of task-specific image-level segmentation and class/task-agnostic bi-directional temporal propagation. DEVA helps 'track anything' without training on video data for every individual task. Check it out!
TADA! Text to Animatable Digital Avatars
TADA is a new approach that takes textual descriptions and produces 3D avatars with high-quality geometry and lifelike textures that can be animated and rendered with graphics pipelines. TADA surpasses existing approaches in both qualitative and quantitative tasks.
Doppelgangers: Learning to Disambiguate Images of Similar Structures
Doppelgangers is a new dataset, which includes image pairs of similar structures. It works based on a learning-based approach to visual disambiguation, formulating it as a binary classification task on image pairs. The comprehensive testing has proved its efficiency.
WavJourney: Compositional Audio Creation with Large Language Models
In this work, the authors tackle creating audio content with storylines combining speech, music, and sound effects, guided by text instructions. They present WavJourney, a system designed to leverage LLMs to connect various audio models for audio content generation.
Gen-2: The Next Step Forward for Generative AI
RunwayML is a platform for artists to use machine learning tools in intuitive ways without any coding experience for media ranging from video, audio, to text. Gen 2 is A multi-modal AI system that can generate novel videos with text, images, or video clips. Check it out!
Courses
New technical deep dive course: Generative AI Foundations on AWS
Generative AI Foundations on AWS" is an 8-hour deep dive course on foundation models in AI. It offers theoretical insights and practical exercises to cover pre-training, fine-tuning, deploying models on AWS, reinforcement learning, performance optimization, and more.
Reproducible Deep Learning: PhD Course in Data Science
Building a DL model is a complex task. The aim of this course is to start from a simple DL model implemented in a notebook, and port it to a ‘reproducible’ world by including code versioning, data versioning, experiment logging, hyper-parameter tuning, etc.





Comments