

At DataPhoenix, we work hard to offer you the best experience with our digest and events. Our goal is to make it easier for you to access the right information in the right place at the right time.
Just to learn more about you, our readers, we decided to launch a small survey initiative. Because the better we know you, the better content we can feature in the digest. Simple.
Push the button below to help us make DataPhoenix better!
Data Phoenix Events
- Charity webinar "dstack – a command-line utility to provision infrastructure for ML workflows" on November 30, 2022 at 16.00 CET by Andrey Cheptsov.
Perhaps you have interesting topics that you would like to share with the world in our charity webinars, we would appreciate it! Your participation could help save someone's life!
ARTICLES
Deep Learning 2.0: Extending the Power of Deep Learning to the Meta-Level
In this article, the authors take deep learning to the next level (DL 2.0) by jointly (meta-)learning hand-crafted elements of the DL pipeline: neural architectures and their initializations, training pipelines and their hyperparameters, self-supervised learning pipelines, etc.
The No-Code Pandas Alternative That Data Scientists Have Been Waiting For
The ability to extract valuable insights from data is a fundamental skill that every organization looks for in a data scientist. In this article, the author discusses how it can be done more easily by using a potential no-code assistive Pandas tool for data analysis called Gigasheet.
Machine Learning Algorithms Cheat Sheet
Machine learning is a complex and diverse field. It can be hard not only for beginners but also for professionals to find their way around various algorithms, tools, services, and theorems. This ultimate machine learning cheat sheet is a quick reference guide to 5 common algorithms. Use it.
Detecting Bad Posture With Machine Learning
This article explores various relevant observational methods for evaluating ergonomics. You will learn how to apply this knowledge in practice to create a working example in Python using a webcam and ML/CV models from Google’s MediaPipe.
Monitoring ML models with Vertex AI
Have you watched any of the SpaceX rocket launches? The idea is, every launch is closely monitored. And when it comes to launching ML models, monitoring is also a must. In this article, we want to show how to enable monitoring for launched ML Models with Vertex AI.
MLOps Pipeline with GitLab in Minutes
This article will educate you how to use GitLab, Heroku, and Ruby to quickly create a seamless CI/CD pipeline. Specifically, you’ll learn to deploy Flask to Heroku with GitLab, implement MLOps pipeline with CI/CD, and automate the MLOps CI/CD pipeline with GitLab.
PAPERS
Scaling Instruction-Finetuned Language Models
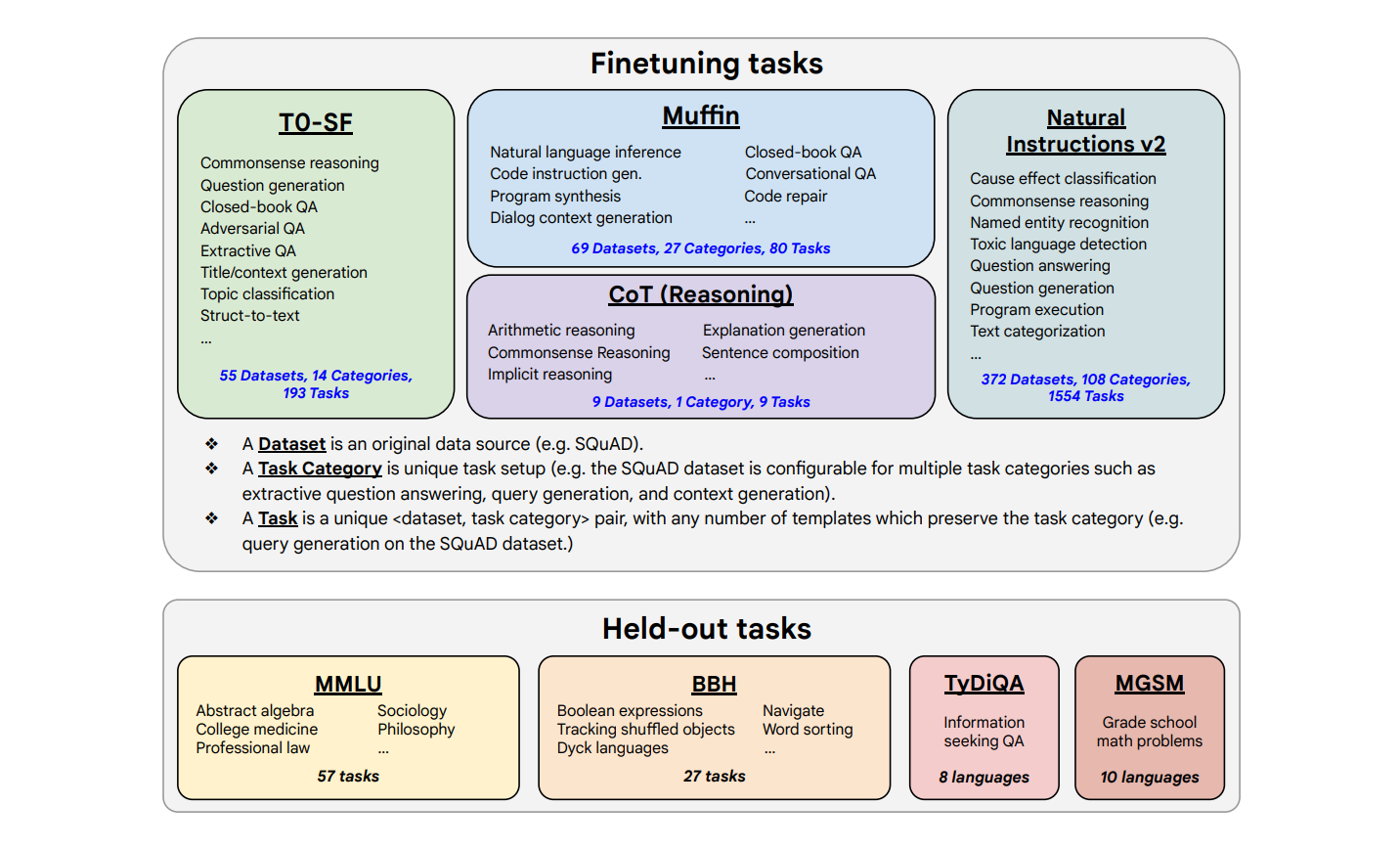
In this paper, authors explore instruction finetuning with a particular focus on scaling the number of tasks, scaling the model size, and finetuning on chain-of-thought data.
Efficiently Scaling Transformer Inference
In this paper, the authors explore the problem of efficient generative inference for Transformer models in one of its most challenging settings: large deep models, with tight latency targets and long sequence lengths. Check out the paper to learn the results of experiments!
Colossal-AI: A Unified Deep Learning System For Large-Scale Parallel Training
Choosing the optimal parallel strategy for Transformer models is extremely challenging, because it requires domain expertise in both deep learning and parallel computing. Colossal-AI introduces a unified interface to scale sequential code of model training to distributed environments.
InternImage: Exploring Large-Scale Vision Foundation Models with Deformable Convolutions
InternImage is a new large-scale CNN-based foundation model that can self-improve from increasing parameters and training data like ViTs. InternImage takes deformable convolution as the core operator and can reduce the strict inductive bias of traditional CNNs.
AnimeRun: 2D Animation Correspondence from Open Source 3D Movies
AnimeRun is a correspondence dataset for 2D-styled cartoons. It provides colored frames and black-and-white contour lines of 2D cartoons and correspondence labels at pixel level and region level. The data is designed to facilitate automatic processing on 2D animation.
PhaseAug: A Differentiable Augmentation for Speech Synthesis to Simulate One-to-Many Mapping
PhaseAug is the first differentiable augmentation for speech synthesis that rotates the phase of each frequency bin to simulate one-to-many mapping. PhaseAug outperforms baselines without any architecture modification without unnecessary overfitting.
We hope that you liked the digest. Kindly help us make DataPhoenix a better place for all readers. Please, take part in our survey — It won’t take more than a few minutes!





Comments