
Meta Fundamental AI Research (FAIR) team on audio hypercompression shows how AI can be used to ensure that audio messages don't glitch or slow down when the Internet connection is poor.
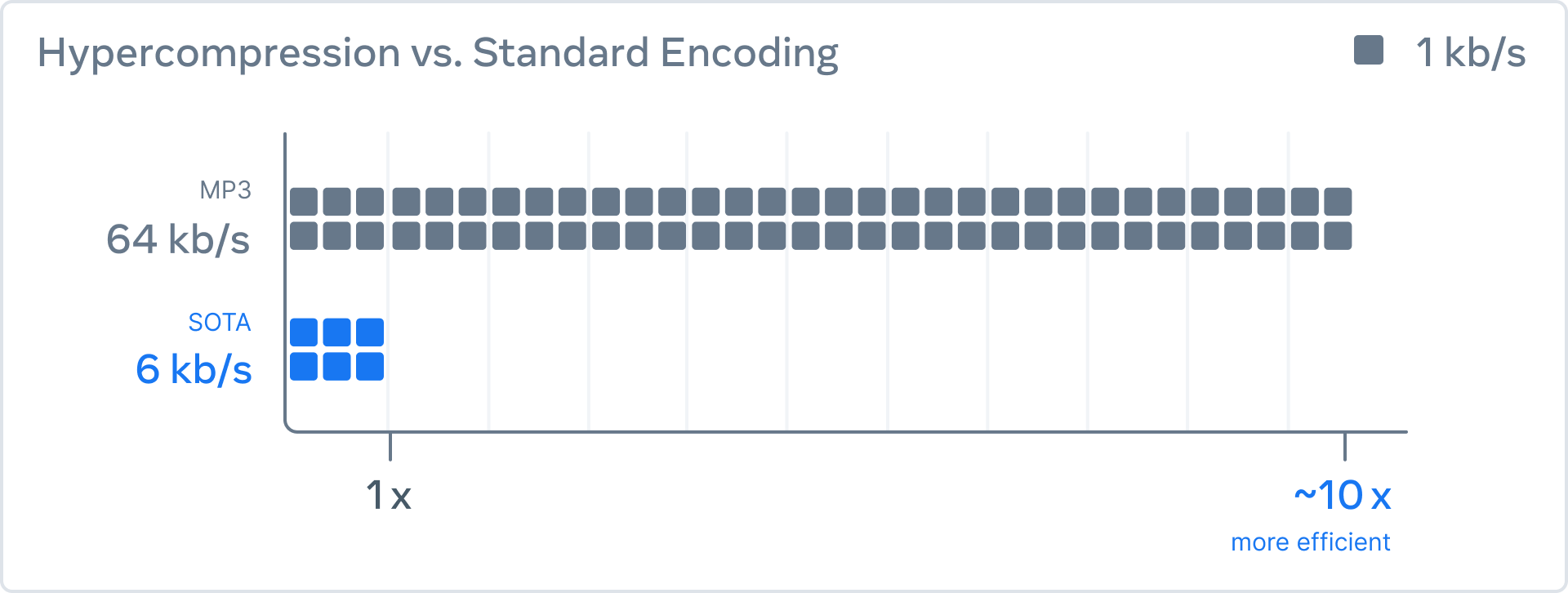
AI researchers have created a three-part system and trained it to compress audio data to a given size. This data could then be decoded using a neural network. They achieved about 10 times the compression rate of MP3 at 64 kbps without loss of quality and were the first to apply it to 48 kHz stereo audio (i.e. CD quality), which is the standard for music distribution.
The new compression technique is based on artificial intelligence. Codecs, which act as encoders and decoders of data streams, provide much of the audio compression used by people on the Internet. Some examples of commonly used codecs include MP3, Opus and EVS. To push the boundaries of what is possible, developers created Encodec, a neural network that learns from start to finish to reconstruct the input signal.
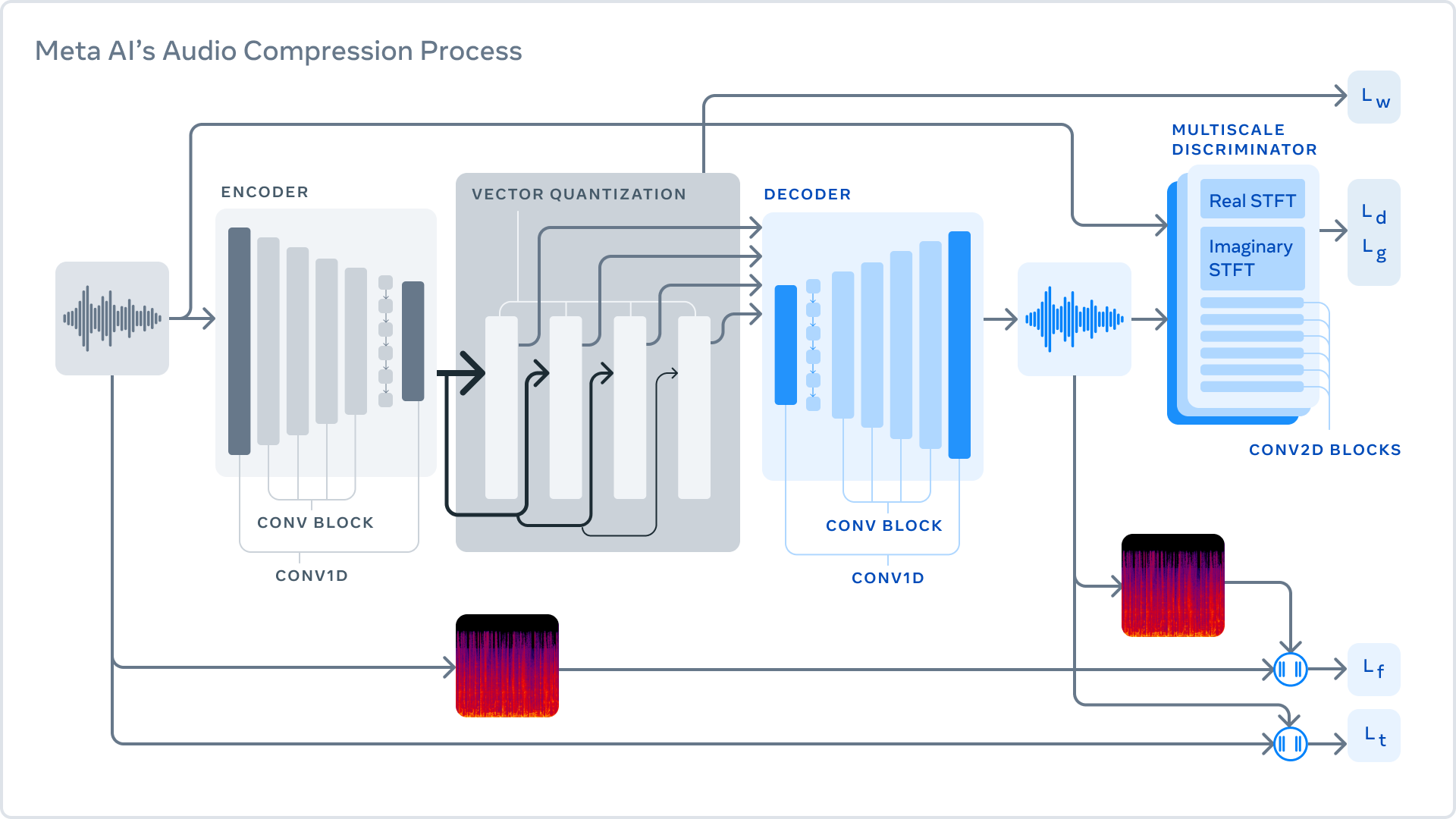
Encodec consists of three parts: the encoder, which takes the uncompressed data and converts it into a higher dimensional and lower frame rate representation, the second part is the quantizer, which compresses this representation to a given size and the last step is the decoder, which transforms the compressed signal back into a waveform as similar to the original as possible. The key to lossy compression is to identify changes that will not be perceived by humans, because at low bitrates a perfect reconstruction is impossible. To do this, discriminators are used to improve the perceptual quality of the generated samples.
These methods do not yet cover video, but it is the beginning of a continuous development, which aims to improve features such as video conferencing, streaming movies and playing with friends in VR.
- Blog post - https://ai.facebook.com/blog/ai-powered-audio-compression-technique/
- Paper - https://arxiv.org/abs/2210.13438
- Code - https://github.com/facebookresearch/encodec
Earlier we wrote about Google Research, who, together with researchers from Tel Aviv University have created a method that alleviates the problem in editing, where even a small change in the text hint often leads to a completely different result. In their work, they use an intuitive prompt-to-prompt editing scheme, where editing is controlled only by the text.





Comments