
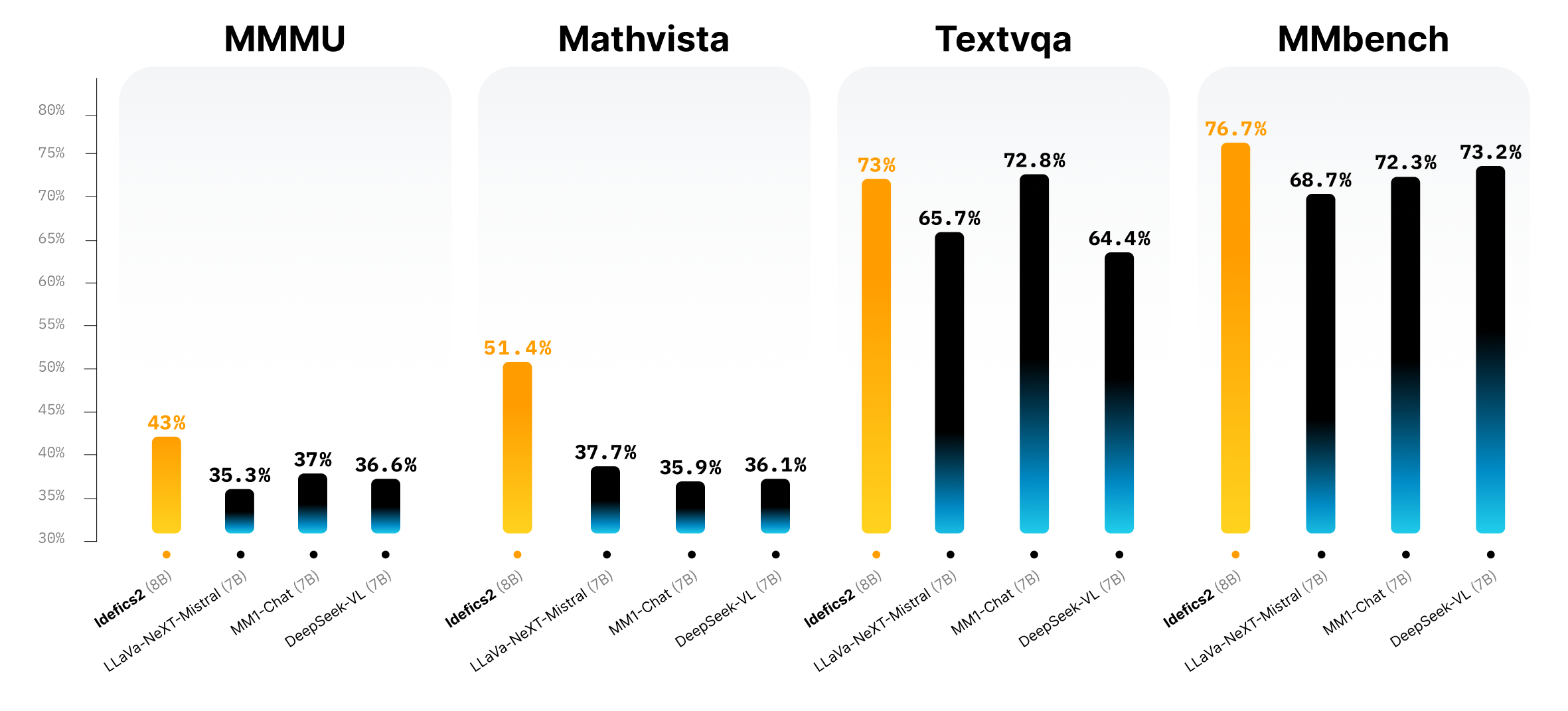
Idefics 2 is an Apache 2.0 licensed, 8B-parameter general multimodal model with enhanced OCR capabilities that can take text and images as input to answer questions about images, describe visual content, generate narratives grounded on image inputs, extract relevant information from documents, and do basic math. Its performance at visual question-answering benchmarks is at the top of its size class and competes with larger-sized models such as LLava-Next-34B and MM1-30B-chat. Idefics 2 is also integrated out-of-the-box in 🤗 Transformers for simplified fine-tuning.
Idefics 2 was trained on openly available datasets, including Wikipedia and OBELICS for interleaved web documents; Public Multimodal Dataset, LAION-COCO for image-caption pairs; PDFA (en), IDL and Rendered-text for OCR data, and WebSight for image-to-code. Instruction fine-tuning was achieved using The Cauldron, a multimodal instruction fine-tuning dataset released in parallel with Idefics 2. The Cauldron compiles 50 manually-curated datasets for multiturn conversations. Additional instruction fine-tuning was performed using text-based instruction fine-tuning datasets. Improvements over the previous Idefics version include image manipulation in the original resolution and aspect ratio to circumvent the need to resize images, enhanced OCR capabilities by feeding the model with data needing to be transcribed from images or documents, and a simpler visual features architecture. Additional information on the dataset, training, and license, plus a "getting started" guide and additional resources, can be found here.





Comments