
Qixun Wang12, Xu Bai12, Haofan Wang12*, Zekui Qin12, Anthony Chen123
Huaxia Li2, Xu Tang2, and Yao Hu2
1InstantX Team 2Xiaohongshu Inc 3Peking University
Abstract
There has been significant progress in personalized image synthesis with methods such as Textual Inversion, DreamBooth, and LoRA. Yet, their real-world applicability is hindered by high storage demands, lengthy fine-tuning processes, and the need for multiple reference images. Conversely, existing ID embedding-based methods, while requiring only a single forward inference, face challenges: they either necessitate extensive fine-tuning across numerous model parameters, lack compatibility with community pre-trained models, or fail to maintain high face fidelity. Addressing these limitations, we introduce InstantID, a powerful diffusion model-based solution. Our plug-and-play module adeptly handles image personalization in various styles using just a single facial image, while ensuring high fidelity. To achieve this, we design a novel IdentityNet by imposing strong semantic and weak spatial conditions, integrating facial and landmark images with textual prompts to steer the image generation. InstantID demonstrates exceptional performance and efficiency, proving highly beneficial in real-world applications where identity preservation is paramount. Moreover, our work seamlessly integrates with popular pre-trained text-to-image diffusion models like SD1.5 and SDXL, serving as an adaptable plugin. Our codes and pre-trained checkpoints will be available at this URL.
Method
Given only one reference ID image, InstantID aims to generate customized images with various poses or styles from a single reference ID image while ensuring high fidelity. Following figure provides an overview of our method. It incorporates three crucial components: (1) An ID embedding that captures robust semantic face information; (2) A lightweight adapted module with decoupled cross-attention, facilitating the use of an image as a visual prompt; (3) An IdentityNet that encodes the detailed features from the reference facial image with additional spatial control.
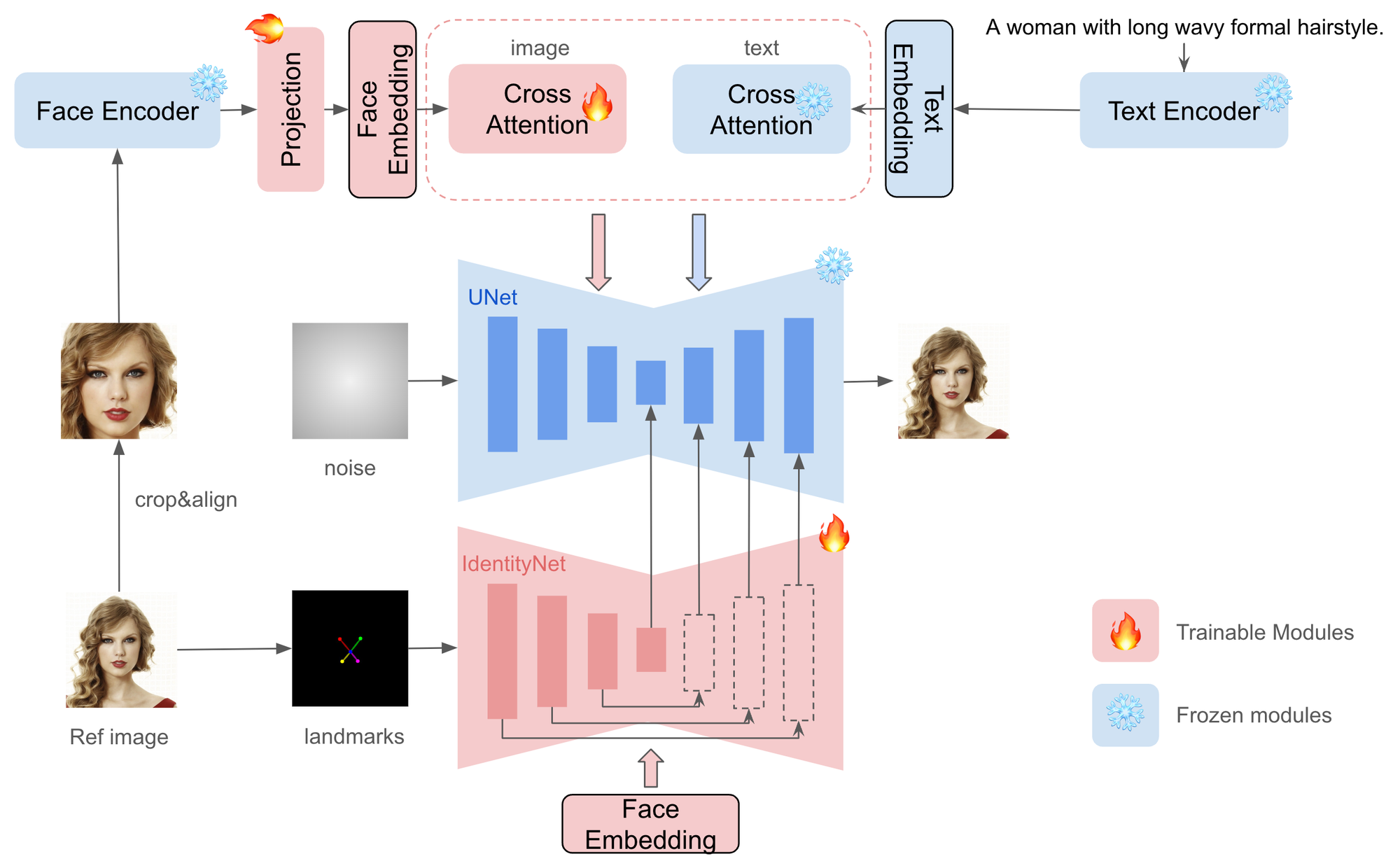
We are different from previous works in the following aspects: (1) We do not train UNet, so we can preserve the generation ability of the original text-to-image model and be compatible with existing pre-trained models and ControlNets in the community; (2) We don't require test-time tuning, so for a specific character, there is no need to collect multiple images for fine-tuning, only a single image needs to be inferred once; (3) We achieve better face fidelity, and retain the editability of text.





Comments