
OLMo-7B is the first of a series of genuinely open-source models that AI2 will release in the coming months. OLMo-7B was built using AI2's Dolma dataset, which is also openly available and thus features all its pre-training data, including the code that produces the training data. The OLMo framework also contains the model weights, inference code, training metrics and logs, and the evaluation suite used during development. The evaluation suite also incorporates over 500 checkpoints per model and evaluation code. The checkpoints were saved every 1000 steps and are available as revisions at Hugging Face.
AI2 plans to do this for future releases and has stated it will include fine-tuning code and adapted models where applicable. In addition to OLMo-7B, the first batch of models includes three other variants at the 7B scale and a smaller model at the 1B scale. As mentioned, AI2 already plans to release more models, including some at larger scales and some instruction-tuned models. The details of OLMo's development can be found in the technical report. The models and materials related to the framework are released under an Apache 2.0 license.
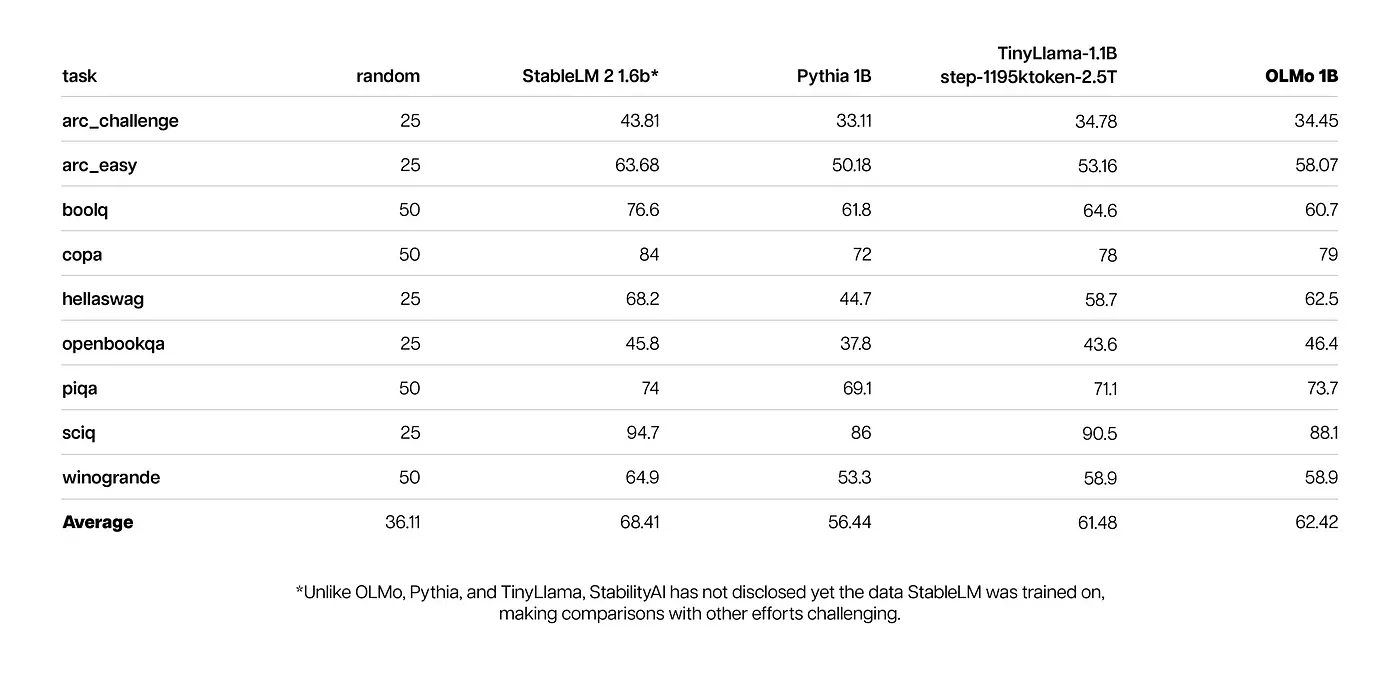
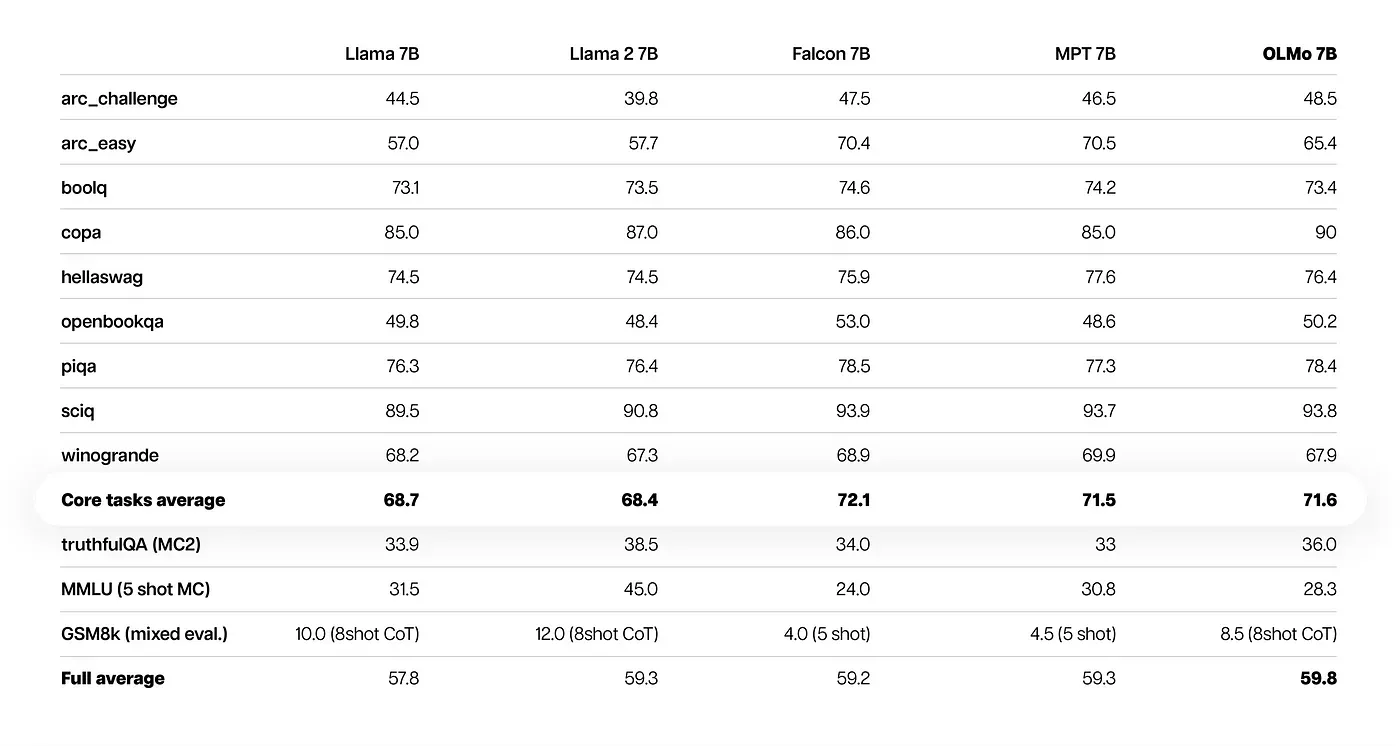
AI2 noted that open-source and partially open-source models EleutherAI's Pythia Suite, MosaicML's MPT models, TII's Falcon models, and Meta's Llama served as benchmarks for OLMo-7B and OLMo-1B. The models were tested using nine internal benchmarks and three more corresponding to the Hugging Face Open LLM Leaderboard. The results showed that OLMo-7B fares slightly better than Llama 2 on many generative and reading comprehension tasks, although it lags at question-answering ones such as MMLU. The following sets of scores were released for both models:
OLMo-1B
OLMo-7B
Aside from gaining insights into the models' performance, AI2 has released all the related training data in the hopes that scientists can accelerate their work and stop depending on qualitative assumptions about models' performance. Open availability also means that researchers and developers can build on results and learn from previous mistakes. Moreover, the open availability of the training data means that redundancies during development can be avoided. This becomes an urgent issue once one considers that a single training round has the same carbon emission rate as nine US homes for one year.
The LUMI supercomputer, known for being one of the greenest supercomputers in the world, made the pre-training work for OLMo possible. Other AI2 partners and collaborators include the Kempner Institute for the Study of Natural and Artificial Intelligence at Harvard University, AMD, CSC (Lumi Supercomputer), the Paul G. Allen School of Computer Science & Engineering at the University of Washington, and Databricks. With an all-star support, it is only reasonable to be excited about what the future will bring for AI2 and the OLMo framework and models.





Comments