
Spatiotemporal Action Detection (STAD) is a fundamental and important task in video understanding. It aims to detect actions in the current input frame and is widely used, for example, in video surveillance and somatosensory games.
Developers are making many changes to the design of YOWO to make it better. For the network structure, they use the same elements of the official YOWO implementation, including 3D-ResNext-101 and YOLOv2, but use the better pre-trained weight of the re-implemented YOLOv2, which is better than the official YOLOv2.
YOWO consists of a 3D framework and a 2D framework. He develops a CFAM (channel and attention fusion module) to fuse 2D spatiotemporal features and 3D spatiotemporal features. He then uses a convolutional layer for prediction.
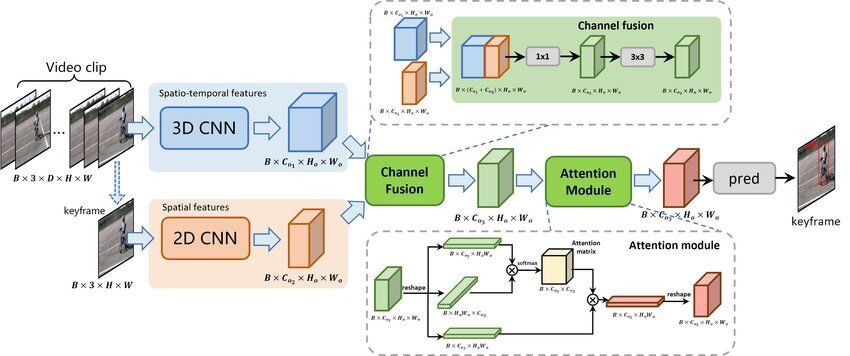
But the developers believe there is still much room for improvement in YOWO , so they optimize it on three sides: the backbone, the label assignment, and the loss function. They use GIoU losses for box-regression to accurately determine action instances. After this incremental improvement, YOWO achieves 84.9% mAP frames and 50.5% mAP video on UCF101-24, significantly higher than the official YOWO. They called the optimized YOWO the YOWO-Plus.
Moreover, by replacing 3D-ResNext-101 with the efficient 3DShuffleNet-v2, the developers created the lightweight YOWO-Nano action detector, which achieves 81.0 percent mAP frames and 49.7 percent mAP video frames at more than 90 FPS on the UCF101-24. It also achieves 18.4% mAP frames at about 90 FPS on the AVA. It is probably the fastest modern action detector.
YOWO-Plus is trained on a training split and evaluated on the most frequent 60 action classes from the AVA dataset, which is a large-scale benchmark for spatiotemporal action detection.
The last post was about AutoAvatar, where researchers made implicit avatar modeling possible for the first time. It is an autoregressive approach for modeling dynamically deforming human bodies directly from raw scans. The approach is an autoregressive model that takes the history of a person's poses and shapes as input, and then creates an implicit surface for the future frame.



Comments