
Data Phoenix Events

Data Phoenix team invites you all to our upcoming "The A-Z of Data" charity webinar that’s going to take place on December 21, 2022 at 16.00 CET.
- Topic: Vertex AI Pipelines infrastructure with Terraform
- Speaker: Alona Slastin, ML Engineer at SoftServe
- Language: English
- Participation: free (but you’ll be required to register)
- Karma perk: donate to our charity initiative
Vertex AI is a Google Cloud Platform service specified on building, deploying and scaling ML models with pre-trained and customizable models. It provides tools for every step of the machine learning workflow across different model types and for different levels of machine learning expertise.
Like any cloud platform, it requires the preliminary deployment of an infrastructure, the enabling of specific services and setting up the permissions. You can do it as a code with open-source software tool Terraform, that allows you to safely and predictably create, change, and improve infrastructure.
During this session we will go through the best practices for developing Vertex AI Pipelines and connect different services together. You will learn how to wrap your infrastructure with Terraform and set up automatic deployment of models using Vertex AI and GCP services.
ARTICLES
Data Version Control with DVC and Git
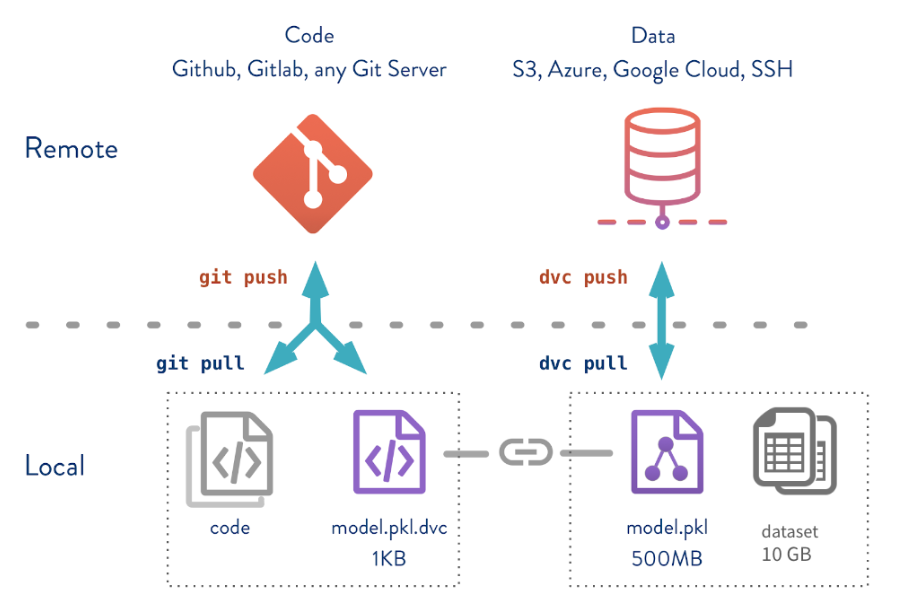
DVC is an open-source project that makes ML models reproducible and shareable. This article will introduce you to DVC and give a brief guide to start to help you to start using it to handle large files, datasets, machine learning models, metrics, and code.
The 5 Stages of Machine Learning Validation
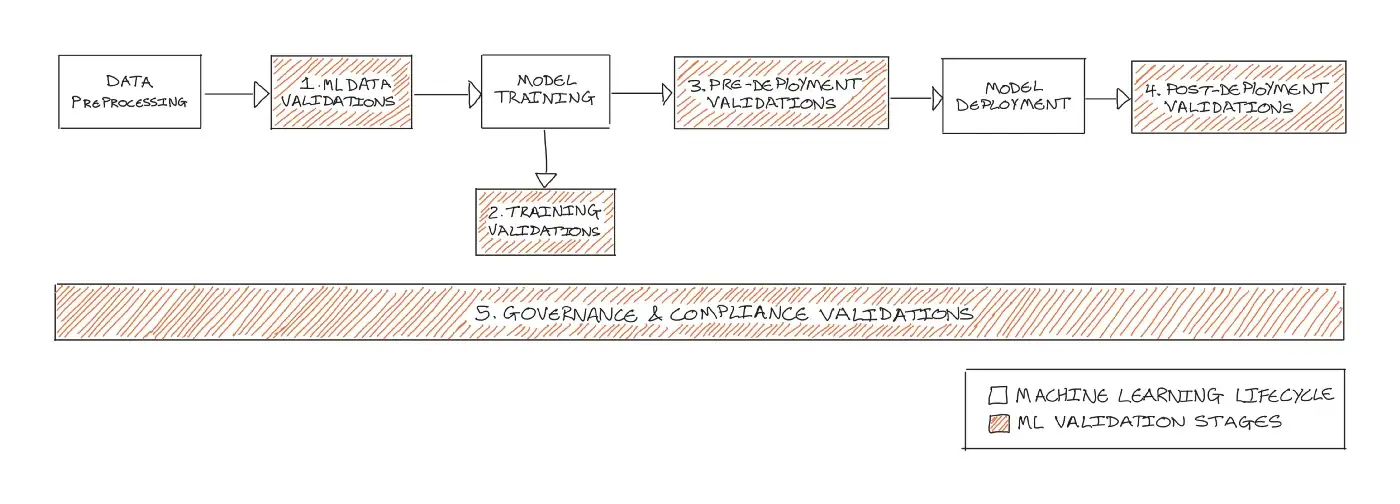
Having a validation process for ML pipelines ensures that ML systems are built with and maintain high-quality; systems are fully compliant and safe to use; stakeholders have visibility on how a model is validated, and the value of ML. Learn more about the process!
Large-Scale Knowledge Graph Completion on Graphcore IPUs
In this article, the authors present Graphcore’s winning submission to the Knowledge Graph track of OGB-LSC@NeurIPS 2022. They provide insights into the ML models, dataset considerations, the ensembling strategy, and their execution scheme that enabled this success.
10 Quick Pandas Tricks to Energize your Analytics Project
Pandas is the popular data analytics library in Python. It certainly provides the flexibility and the tools data professionals need to handle their data. In this article, the author shares 10 quick yet highly useful tricks in Pandas, which you can master in under 10 minutes.
Unlock the Latest Transformer Models with Amazon SageMaker
AWS DLCs are popular for training and deploying NLP models on SageMaker, but sometimes the latest versions of the Transformers library are not available in the prebuilt DLCs. In this article, you’ll learn how to extend DLCs to train and deploy the latest Hugging Face models on AWS.
River: Online Machine Learning in Python
River is a Python library for online machine learning. In this article, you’ll learn about using River as a fast and cheap approach for updating your ML models in production, in application to online learning. Check out the article for a detailed guide!
How to Run SQL Queries On Your Pandas DataFrames With Python
Pandas is used by Data Scientists and Data Analysts for data analysis purposes. SQL is known for its performance, being human-readable, and can be easily understood even by non-technical people. This article demonstrates how you can use the two to gain a competitive advantage.
PAPERS & PROJECTS

InstructPix2Pix is a conditional diffusion model that is trained on generated data, and generalizes to real images and user-written instructions at inference time. It demonstrates compelling editing results for a diverse collection of input images and written instructions. Check it out!
Strong-TransCenter: Improved Multi-Object Tracking based on Transformers with Dense Representations
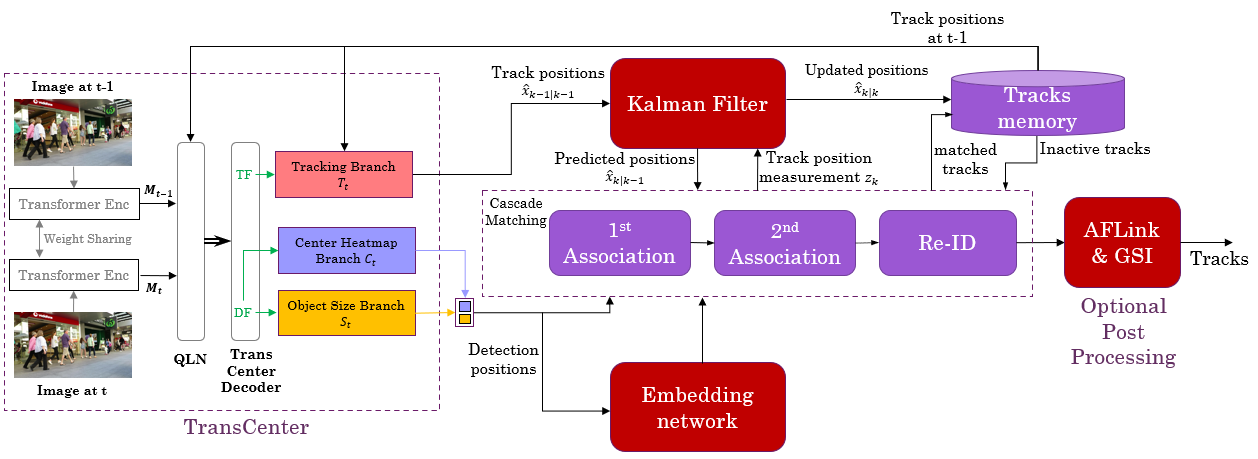
In this paper, the authors show an improvement to TransCenter using post processing mechanism based in the Track-by-Detection paradigm: motion model estimation using Kalman filter and target Re-identification using an embedding network. Learn how they delivered the improvements!
DAMO-YOLO: A Report on Real-Time Object Detection Design
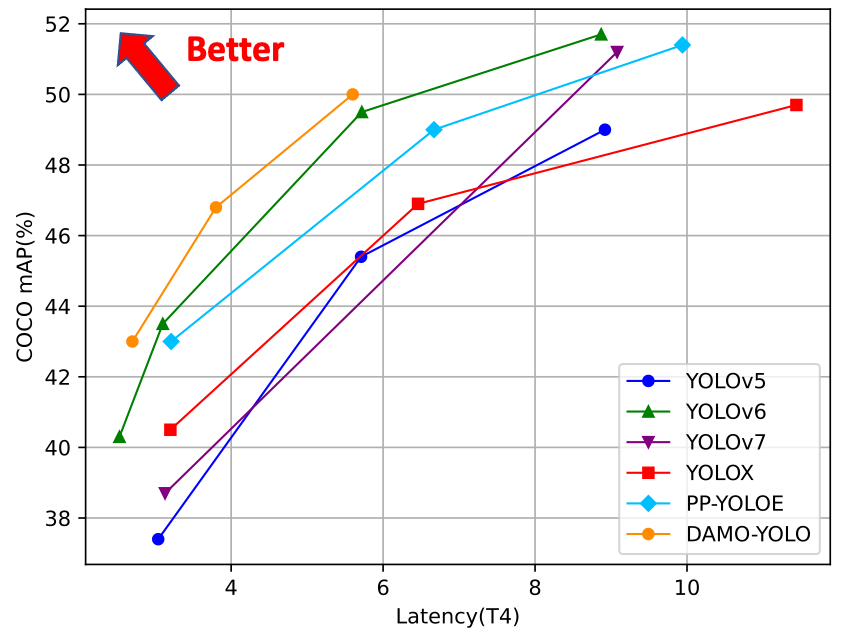
DAMO-YOLO is a fast and accurate object detection method that achieves higher performance than the state-of-the-art YOLO series. DAMO-YOLO is extended from YOLO with some new technologies. Learn more about its results here!
ReFace: Improving Clothes-Changing Re-Identification With Face Features
In this work, a new method that takes advantage of the ability of existing ReID models to extract appearance-related features is introduced. It combines it with a face feature extraction model to achieve new state-of-the-art results, both on image-based and video-based benchmarks.
InfiniteNature-Zero
Zhengqi Li et al. present a method for learning to generate unbounded flythrough videos of natural scenes starting from a single view. Learn more about their novel self-supervised view generation training paradigm, where they sample and rendering virtual camera trajectories.
DiffusionInst: Diffusion Model for Instance Segmentation
DiffusionInst is a novel framework that represents instances as instance-aware filters and formulates instance segmentation as a noise-to-filter denoising process. Experiments on COCO and LVIS show that it achieves competitive performance compared to existing instance segmentation models.
DiffusionBERT: Improving Generative Masked Language Models with Diffusion Models
DiffusionBERT is a new generative masked language model based on discrete diffusion models. Experiments on unconditional text generation demonstrate that it achieves significant improvement over existing diffusion models for text and generative masked language models.






Comments