
Data Phoenix Events

Data Phoenix team invites you all to our upcoming "The A-Z of Data" charity webinar that’s going to take place on December 21, 2022 at 16.00 CET.
- Topic: Vertex AI Pipelines infrastructure with Terraform
- Speaker: Alona Slastin, ML Engineer at SoftServe
- Language: English
- Participation: free (but you’ll be required to register)
- Karma perk: donate to our charity initiative
Vertex AI is a Google Cloud Platform service specified on building, deploying and scaling ML models with pre-trained and customizable models. It provides tools for every step of the machine learning workflow across different model types and for different levels of machine learning expertise.
Like any cloud platform, it requires the preliminary deployment of an infrastructure, the enabling of specific services and setting up the permissions. You can do it as a code with open-source software tool Terraform, that allows you to safely and predictably create, change, and improve infrastructure.
During this session we will go through the best practices for developing Vertex AI Pipelines and connect different services together. You will learn how to wrap your infrastructure with Terraform and set up automatic deployment of models using Vertex AI and GCP services.
ARTICLES
Bringing GitOps to ML with dstack

In the AI/ML space, GitOps is still at the trial stage and isn’t adopted at scale yet. In this article, you’ll learn some of the ideas around GitOps and ML with dstack. You’ll find it relevant if you’re curious about productizing ML models and the dev tooling around it.
“You Can’t Predict the Errors of Your Model”… Or Can You?
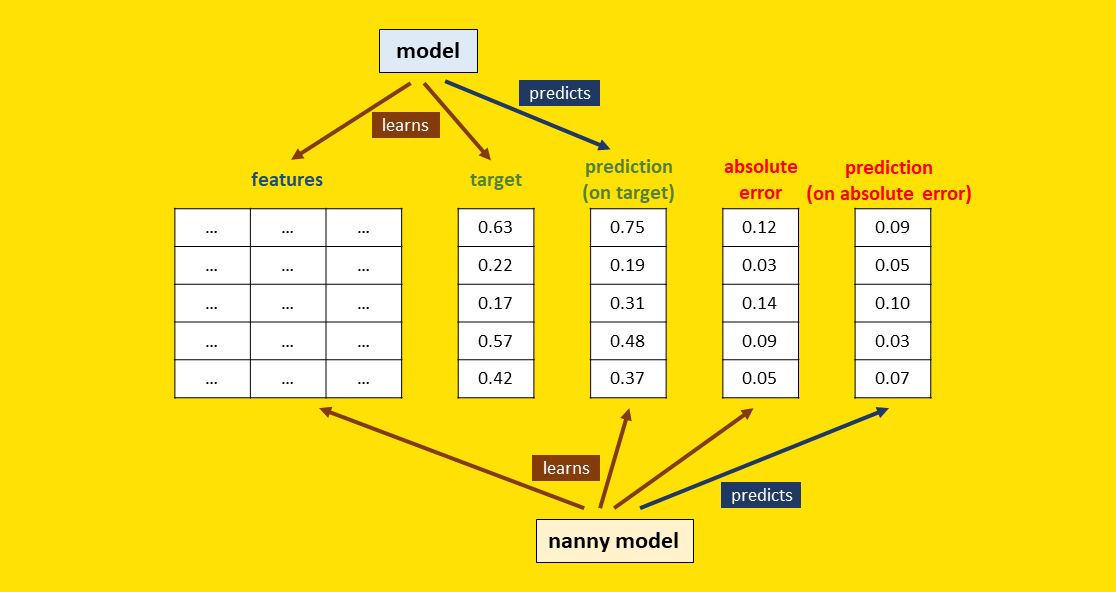
Can you get access to early feedback about how your regression models are performing in production? Yes, with a method called Direct Loss Estimation (DLE) that allows estimating the performance of any regression model, when the ground truth is not available.
Retrieval Transformer Enhanced Reinforcement Learning
Recently, a new type of Transformer called the Retrieval Transformer has been growing in popularity because of its efficiency. In this article, you’ll find out how the author has incorporated it into his RL agent to achieve promising results and get valuable feedback.
Time Series Analysis Introduction — A Comparison of ARMA, ARIMA, SARIMA Models
Time Series is a certain sequence of data observations that a system collects within specific periods of time. In this article, you’ll take a big picture view at it, starting with the basics and moving to the overview of various time series analysis models.
DeepSpeed Deep Dive — Model Implementations for Inference (MII)
DeepSpeed has recently released a new open-source library called Model Implementation for Inference. This article explains some of the underlying technologies and the associated terminology, and zooms in on a few special, deep features of the MII library.
Choosing the Best ML Time Series Model for Your Data
When it comes to time series models for machine learning, you have more than a plenty of choices, and this becomes a problem. This article explores major ML time series models and offers a framework for choosing the right one for your ML tasks.
DeepAR: Mastering Time-Series Forecasting with Deep Learning
Time series models have made great strides over the last couple of years. Just recently, such models have worked on a single sequence only, but now the number of the use and application choices is over the roof. This article dives into DeepAR, to explain the DL side of the problem.
Hybrid (multimodal) neural network architecture: Combination of tabular, textual and image inputs to predict house prices.
Can you simultaneously train structured (tabular) and unstructured (text, image) data in the same neural network model while optimizing the same output target? The author perform the experiment by implementing a “concat” combination method.
PAPERS & PROJECTS
DiffusionDet: Diffusion Model for Object Detection
DiffusionDet is a new framework that formulates object detection as a denoising diffusion process from noisy boxes to object boxes. It achieves favorable performance compared to previous well-established detectors. Learn about two important findings of the team!
Galactica: A Large Language Model for Science
Galactica is a large language model that can store, combine, and reason about scientific knowledge. It is trained on a large scientific corpus of papers, reference material, and knowledge bases to outperform existing models on a range of scientific tasks. Check out the demo and the paper!
Creative Writing with an AI-Powered Writing Assistant: Perspectives from Professional Writers
In this paper, the authors commissioned 13 professional, published writers from a diverse set of creative writing backgrounds to craft stories using Wordcraft, a text editor with built-in AI-powered writing assistance tools. Learn more about the ways to improve AI writing!
Versatile Diffusion: Text, Images and Variations All in One Diffusion Model
The authors expand the existing single-flow diffusion pipeline into a multi-flow network, dubbed Versatile Diffusion (VD), that handles text-to-image, image-to-text, image-variation, and text-variation in one unified model. Find more about the results!
Fast Text-Conditional Discrete Denoising on Vector-Quantized Latent Spaces
Paella is a novel text-to-image model requiring less than 10 steps to sample high-fidelity images, using a speed-optimized architecture allowing to sample a single image in less than 500ms, while having 573M parameters. Find out how it works!
CodeGen: An Open Large Language Model for Code with Multi-Turn Program Synthesis
CODEGEN is a family of large language models up to 16.1B parameters based on natural language and programming language data, and open source the training library JAXFORMER. It is competitive with the previous state-of-the-art code generation. Learn about other benchmarks!
Forces are not Enough: Benchmark and Critical Evaluation for Machine Learning Force Fields with Molecular Simulations
In this paper, the researchers introduce a novel benchmark suite for ML MD simulation. They curate and benchmark representative MD systems, including water, organic molecules, peptide, and materials, to design evaluation metrics corresponding to the scientific objectives.





Comments