

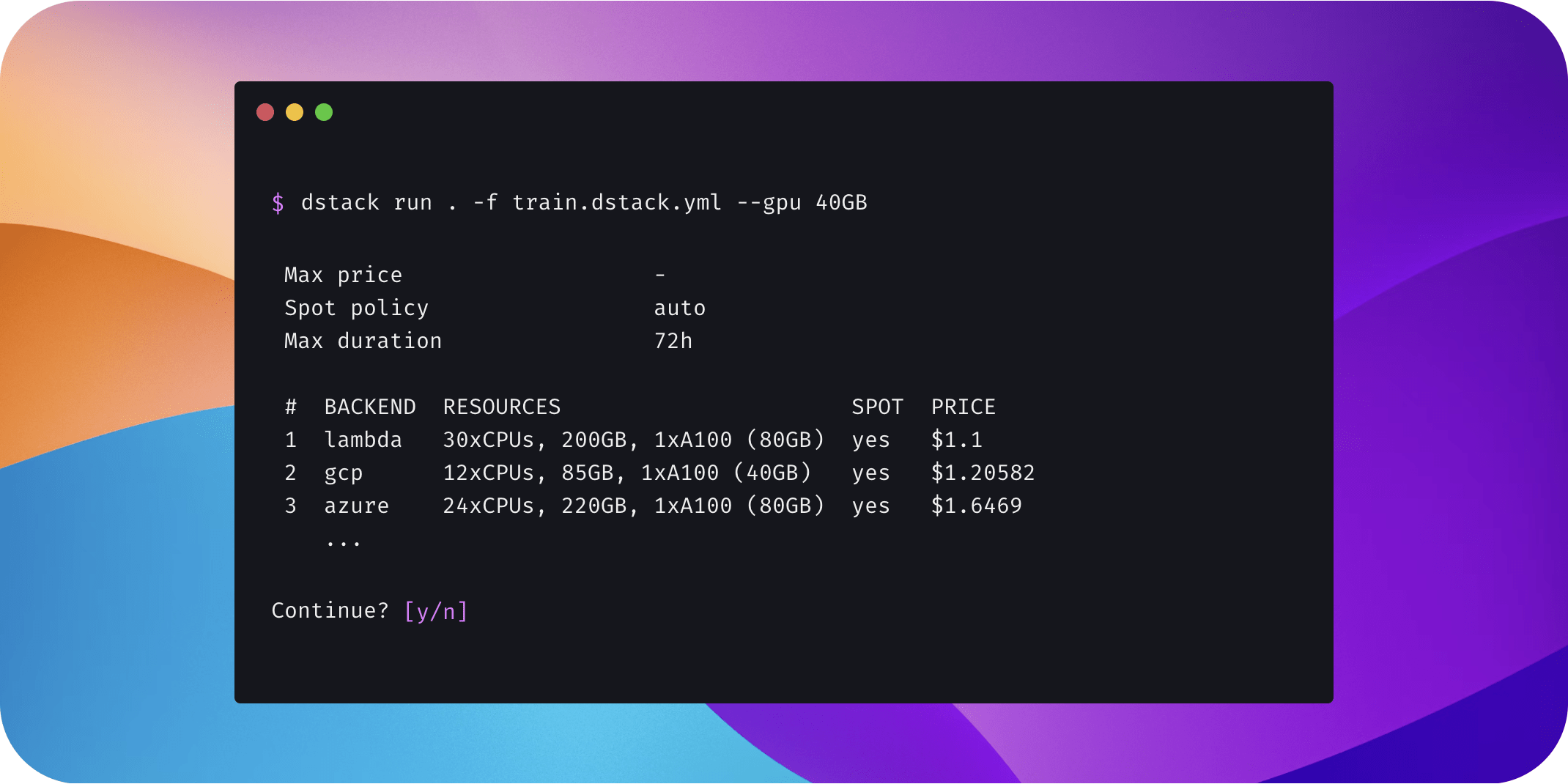
The partner of this issue is dstack, an open-source platform for training and deploying generative AI models. The platform provides a CLI and Python API to easily train and deploy models while utilizing your own cloud account.
Explore the quickstart guide and various examples to learn how to leverage open-source and custom LLMs without requiring any engineering efforts.
Welcome to this week's edition of Data Phoenix Digest! This newsletter keeps you up-to-date on the news in our community and summarizes the top research papers, articles, and news, to keep you track of trends in the Data & AI world!
Be active in our community and join our Slack to discuss the latest news of our community, top research papers, articles, events, jobs, and more...
Data Phoenix's upcoming webinars:

MLOps for Ads Ranking at Pinterest
Join us for a talk on the journey of scaling ads ranking at Pinterest by innovations in machine learning algorithms and the ML ecosystem beginning from traditional logistic regressions to more complex transformers models, and advancements in ML platform offerings through unified feature representation, shared feature store, and standardized inference services. Throughout the process, we encountered various challenges and gained valuable lessons. Discover the hurdles we overcame and the insights we gained in this talk, as we share the transformation of ads ranking at Pinterest and the lessons learned along the way.
Speaker: Aayush Mudgal is a Senior Machine Learning Engineer at Pinterest, currently leading the efforts around Privacy Aware Conversion Modeling. He has a successful track record of starting and executing 0 to 1 projects, including conversion optimization, video ads ranking, landing page optimization, and evolving the ads ranking from GBDT to DNN stack. His expertise is in large-scale recommendation systems, personalization, and ads marketplaces. Before entering the industry, Aayush conducted research on intelligent tutoring systems, developing data-driven feedback to aid students in learning computer programming. He holds a Master's in Computer Science from Columbia University and a Bachelor of Technology in Computer Science from Indian Institute of Technology Kanpur.
- Building Customized CV Applications with FiftyOne Plugins
Jacob Marks (ML Engineer and Developer Evangelist at Voxel51)/November 2 - Gen AI data chain at scale
Tibor Mach (ML Solutions Engineer at Iterative.ai) / November 15
Summary of the top articles and papers
Articles
Data Drift Monitoring and Its Importance in MLOps
The effectiveness of ML models depends on the quality of how they are monitored and managed; i.e. MLOps. One crucial aspect of MLOps is managing “data drift.” This article explores the ins and outs of data drift to help you manage your MLOps pipelines.
Interactive Fleet Learning
“Interactive Fleet Learning” (IFL) refers to robot fleets in industry and academia that fall back on human teleoperators when necessary and continually learn from them over time. This article introduces new formalisms, algorithms, and benchmarks for IFL. Check it out!
PyTorch/XLA SPMD: Scale Up Model Training and Serving with Automatic Parallelization
PyTorch/XLA SPMD is the integration of GSPMD, an automatic parallelization system for ML workloads, into PyTorch with an easy to use API. It allows PyTorch users to parallelize their ML workloads with less effort and with better performance. Learn more in this blog post!
Effortlessly Build Machine Learning Apps with Hugging Face’s Docker Spaces
The Hugging Face Hub is a platform for collaborative ML. Recently, the team added support for Docker Spaces, enabling users to create custom apps by writing a Dockerfile. This guide explores the basics of creating a Docker Space, configuring it, and deploying code to it.
MLflow Made Easy: Your Beginner’s Guide
MLflow is an open source platform for managing the end-to-end machine learning lifecycle. It is equipped with a robust tracking capability, allowing users to track experiments, to record and compare parameters and results. Check out this guide for beginners to learn more!
Papers & projects
AnomalyGPT: Detecting Industrial Anomalies using Large Vision-Language Models
AnomalyGPT is a novel approach to Industrial Anomaly Detection (IAD) that is based on LVLM. AnomalyGPT achieves state-of-the-art performance with an accuracy of 86.1%, an image-level AUC of 94.1%, and a pixel-level AUC of 95.3% on the MVTec-AD dataset.
LLaVA: Large Language and Vision Assistant
LLaVA is a novel end-to-end trained large multimodal model that combines a vision encoder and Vicuna for general-purpose visual and language understanding. It achieves impressive chat capabilities, compared to GPT-4, setting a new accuracy standard on Science QA.
3D Gaussian Splatting for Real-Time Radiance Field Rendering
Achieving state-of-the-art visual quality while maintaining competitiveness in regard to training times, resources, and high-quality real-time novel-view synthesis is challenging. Check out this research to learn how the authors manage to resolve these problems.
MarioGPT: Open-Ended Text2Level Generation through Large Language Models
MarioGPT is a fine-tuned GPT2 model trained to generate tile-based game levels. It can easily generate diverse levels and can be text-prompted for controllable level generation, addressing key challenges of PCG techniques. Check out the project’s GitHub!
InstaFlow: One Step is Enough for High-Quality Diffusion-Based Text-to-Image Generation
MarioGPT is a novel text-conditioned pipeline designed to turn Stable Diffusion (SD) into an ultra-fast one-step model, in which reflow plays a critical role in improving the assignment between noise and images. Learn more about the impressive results of the research team!





Comments