
Data Phoenix Events

The Data Phoenix team invites you all to our upcoming "The A-Z of Data" charity webinar that’s going to take place on November 9, 2022 at 16.00 CET.
- Topic: “Learning Through Machine Learning: How We Built a Recommendation System from Scratch”.
- Speaker: Dora Petrella, Senior Data Scientist at METRO.digital.
- Language: English.
- Participation: free (but you’ll be required to register).
- Karma perk: donate to our charity initiative.
News
- Shutterstock to integrate OpenAI’s DALL-E 2 and launch fund for contributor artists
- Oracle and NVIDIA collaborate to accelerate adoption of AI in the enterprise
- The fifth edition of The State of AI in the Enterprise
PAPERS
LION: Latent point diffusion models for generating 3D shapes
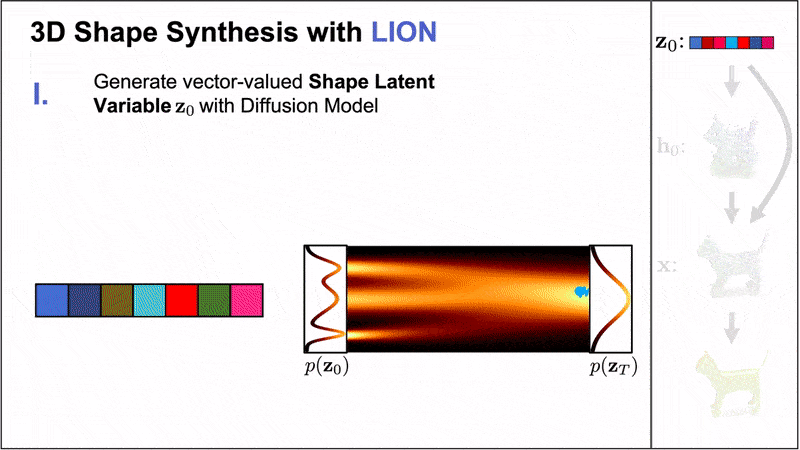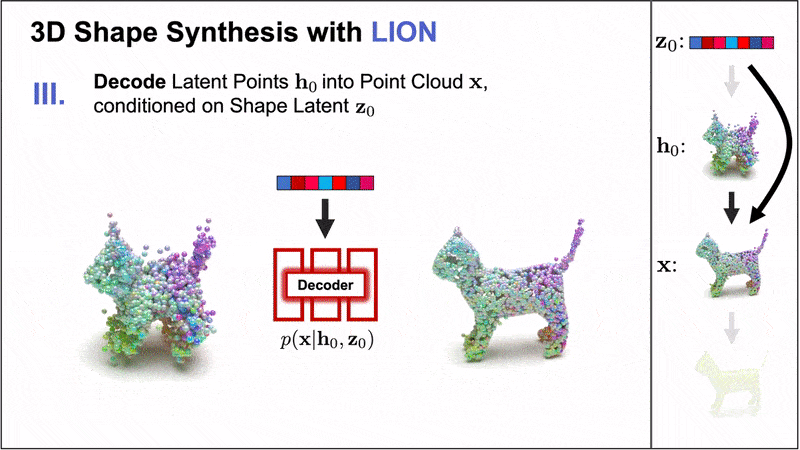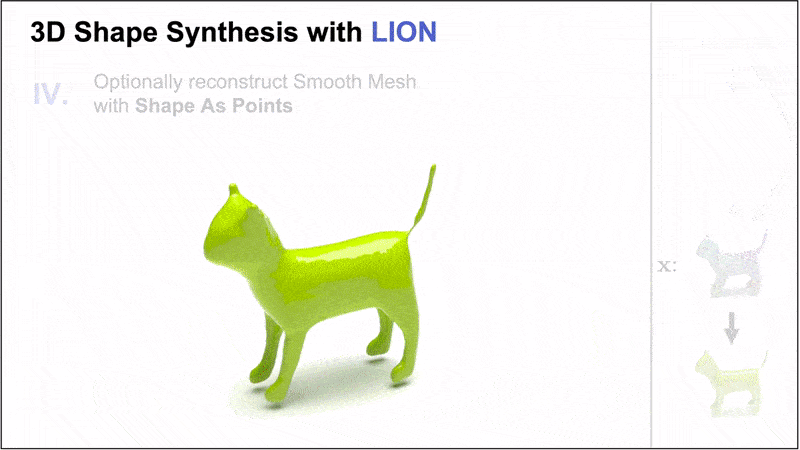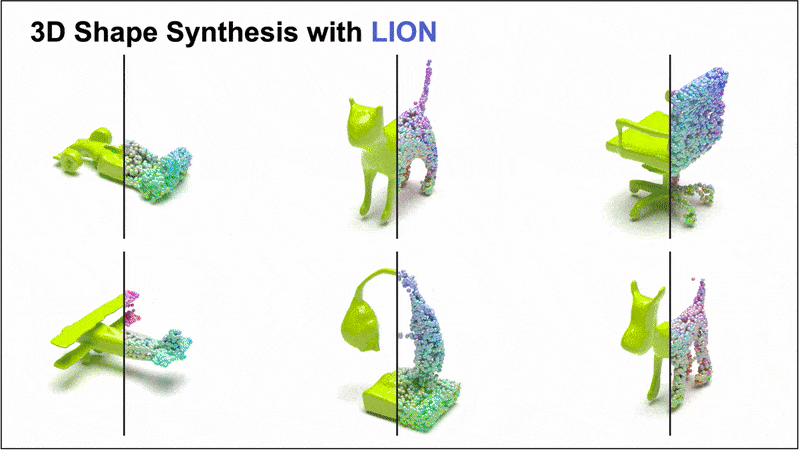
Nvidia introduced the Latent Point Diffusion Model (LION), a DDM for 3D shape generation. LION focuses on learning a 3D generative model directly from geometry data without image-based training.
Omni3D: A Large Benchmark and Model for 3D Object Detection in the Wild

Omni3D is a large benchmark and model for detecting 3D objects in the wild, which uses and merges existing datasets, resulting in 234,000 images annotated with more than 3 million instances and 97 categories.
EVA3D: Compositional 3D Human Generation from 2D Image Collections
EVA3D is a high-quality unconditional 3D human generative model that only requires 2D image collections for training, to achieve state-of-the-art 3D human generation performance.
Text2Light: Zero-Shot Text-Driven HDR Panorama Generation
Text2Light is a zero-shot text-driven framework that generates 4K+ resolution HDRIs without paired training data. The ability of Text2Light to generate high-quality HDR panoramas is proven.
Ask Me Anything: A Simple Strategy for Prompting Language Models
Large language models (LLMs) transfer well to new tasks out-of-the-box if given a natural language prompt. This paper proposes a new method of prompt generation called AMA (Ask Me Anything).
State-of-the-Art Generalization Research in NLP: A Taxonomy and Review
The authors propose a way for creating and evaluating generalizations in NLP. They present an analysis of the current state of generalization research, and make recommendations for the future.
Modelverse: DL Model Collection
Modelverse is a model sharing platform that contains a diverse set of deep generative models, such as animals, landscapes, portraits, and art pieces. Search for whatever model you want. Try now!
ARTICLES
Reinforcement Learning with SARSA — A Good Alternative to Q-Learning Algorithm
SARSA is a State-Action-Reward-State-Action algorithm that is similar to Q-Learning algorithms. In this article, you’ll learn how to use it to teach intelligent agents to play simple games.
How I Passed the AWS Machine Learning Specialty Certification
AWS remains the leader among cloud service providers. No wonder that its specialty certifications are highly coveted on the market. Here’s a step-by-step, practical guide how to get one of them.
Out-of-Distribution Detection via Embeddings or Predictions
Ensuring proper reliability is often a challenge in today’s ML systems based on Out-Of-Distribution (OOD) inputs. Find two much simpler methods to effectively detect outliers in this post!
Orchestrating Data/ML Workflows at Scale With Netflix Maestro
At Netflix, Data and ML pipelines are the core of many business use cases. In this article, the team shares their experience with Maestro, a powerful, at-scale workflow orchestrator.
Language Understanding with BERT
BERT is a deep learning model that is used for numerous different language understanding tasks. Check out this detailed guide on BERT to learn about the ins and outs of this popular DL model.
COURSES
AI Research Experiences: Harvard CS197
This course will introduce to you the practical skills for applied deep learning work, from basic technical writing skills for AI research to composing a full research paper. Check it out!
We hope that you liked the digest. Kindly help us make DataPhoenix a better place for all readers. Please, take part in our survey — It won’t take more than a few minutes!





Comments